|
|
Почему поисковые боты ненавидят логи веб-серверов
|
 |
31.07.2013, 11:39
|
|
#1
|
|
Регистрация: 02.07.2012
Сообщений: 648
|
| Почему поисковые боты ненавидят логи веб-серверов
|
Вы любите футбол или баскетбол? Что общего у этих спортивных игр с СЕО? А общее здесь то, что как в спорте есть не спортивное поведение и нарушение правил в виде технических фолов, так и SEO маркетологи и разработчики часто совершают SEO фолы, обычно это происходит при разработке архитектуры сайта или публикации контента. Кто с этим не согласен, может дальше не читать.
Как оптимизаторы, мы используем все доступные технические средства, чтобы результат продвижения сайта был максимально лучшим в оптимально кратчайшие сроки, а в этом нам помогают: веб-аналитика, краулеры поисковиков Google и Bing, ну и прочие инструменты вебмастеров. Ну, и что же тут необычного во всех этих полезных инструментах, а то что в них есть свои недочёты, из-за того что у поисковиков свои многочисленные секреты, которые не для общего пользования, а из-за этого у нас в процессе продвижения появляются малоприятные белые пятна. Где же найти то, что восполнит нам белые пятна, тоесть то, что сами поисковые системы скрыть от нас ни как не смогут, как бы они этого не желали? Для решения этого вопроса существует, только один истинный источник – это логирование серверов или журналы событий, которые фиксят логами все происходящие события на наших сайтах, в том числе и то, как поисковые боты парсят страницы наших сайтов. Итак, заглядывайте чаще в журналы веб-серверов. Тогда многие события вы будете не просто созерцать, а предугадывать, как Нострадамус и главное у вас будет 100% СЕО зрение.
Самый жирный плюс логирования веб-сервером всех событий в том, что еще за целые сутки до отчёта в бесплатном Google Analytics, мы уже можем видеть ситуационную картину событий на сайте и в работе с логами журналов большим подспорьем служит AWStats.
Что же интересного скрыто в журналах? Помимо ошибок или сбоев в работе, можно дополнительно почерпнуть информацию по многочисленным узким местам сайта, к примеру в логах веб-сервера можно найти:
1. важные сообщения о зафиксированных проблемах в кодах ответа сервера (404, 302, 500 и т.д.).
2. сообщения о выявленном дублированном контенте и т.д.
Приступим к расшифровке логов.
Шаг № 1: Извлечение файла журнала
Журналы веб-серверов могут быть представлены во многочисленных форматах файлов и поэтому метод получения логов зависит в основном от типа сервера, на котором шуршит сайт. Среди самых популярных веб-серверов можно выделить Apache и Microsoft IIS. Поэтому мы тоже не будем лезть в экстраординарные случаи и возьмём за базис для статьи файлы журналов Apache.
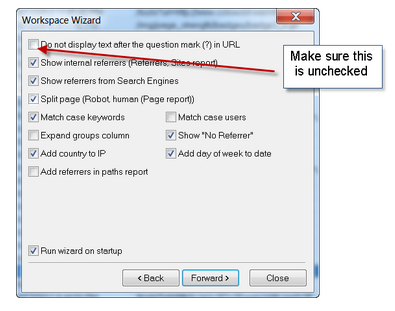
Для сисадминов, которые конфигурируют и обслуживают сервера аналитика и логирование журналов обычное занятие, поэтому можно к ним обратиться, как к службе техподдержки. Мои же советы в этой статье, хоть и обывательские, но для работы сойдут. Первоначально я рекомендую вам зарезервировать объём в 1 Гб для логов сервера, хотя этот объём не критичен. Некоторые хостинг-компании позволяют хранить журналы в вашем корневом каталоге сайта в папке журналы, именно там и доступны все логи о произошедшем за сутки. Поэтому перейдите в эту директорию и убедитесь, какие категории активны в ваших журналах, желательно, чтоб были опционально активны столбцы:
• Host: используется для отфильтровки внутреннего трафика.
• Date: позволяет делать сравнительный анализ за день или несколько суток
• Page/File: показывает в каких каталогах и файлах во время скрапинга выявлены эндемичные вопросы.
• Response code: содержит характеристики ответа сервера, в своём роде типа тонометра, показывая состояние на - (200), (404), (503) и т.д.
• Referrers: для анализа поисковых роботов не критично, но для оценки другого типа трафика очень даже.
• User Agent: тут будут запросы поисковых ботов, которые посетили наш сайт и без этого поля анализ логов теряет свою актуальность.
Нюанс с Apache лог-файлами в том, что они по умолчанию не содержат поля «Referrers», поэтому чтоб мы имели возможность для аналитики этой информации нам надо попросить сисопа для активации этого поля и дальнейшего представления лога сервера в следующем формате:
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-agent}i\""
Для Apache 1.3 нужно просто " combined CustomLog log/acces_log combined "
Для тех, кто самостоятельно предпочитает логирование настроить вручную, то вам нужно создать директивы в файле httpd.conf с одним из выше упомянутых параметров. Более детально на эту тему здесь.
Шаг № 2: Разбор файла журнала
Итак, с настройками покончили и перед нами конечный продукт, архивированный файл журнала под названием «mylogfile.gz», теперь то самое время распарсить его миллиметр за миллиметром. Для этого существуют различные бесплатные и платные анализаторы/парсеры файлов журналов. Мой выбор в главных критериях отбора этих анализаторов в том, чтоб были поддерживаемы: возможность просмотра исходных данных, возможность фильтрации перед парсингом и возможность экспорта в CSV. Поэтому самым подходящим по всем критериям оказался Web Log Explorer , который я использую уже на протяжении нескольких лет. Я буду, использовать его в связке с Excel для демонстрации. AWstats, упомянутый в начале статьи не так гибок и опционален, поэтому он подходит только для поверхностного анализа, по сравнению с Веблогэксплорером.
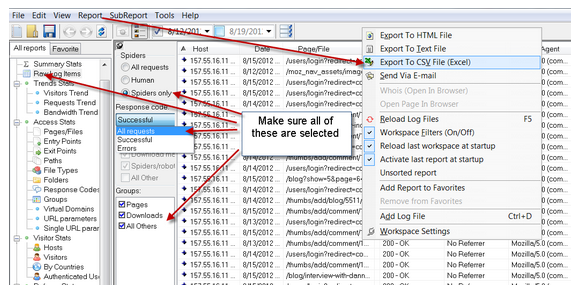
Первое с чего начнём, это импортирования лог-файла для дальнейшего анализа. На этом этапе проблем возникнуть не должно, так как большинство парсеров веб-журналов поддерживают различные форматы лог-файлов и имеют простой встроенный мастер импорта. В первую итерацию парсинга при анализе, я оцениваю общую ситуационную обстановку, поэтому не применяю ни каких фильтров. Но для наглядности, я результаты парсинга импортирую в Excel.
Так что, используя встроенный мастер импорта: не забудьте включить – отображать параметры в URL строку. Дальше, я покажу, как эта опция поможет нам найти пути решения обнаруженных проблем, а также потенциальные источники дублированного контента.
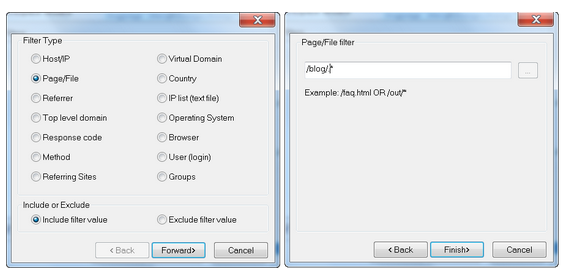
Кому нравится работать с регулярными выражениями, то здесь вам сам бог велел их использовать на всю катушку, для фильтрации данных в генерируемом отчёте. Например, если вы просто хотите, чтобы был проанализирован трафик в конкретном разделе сайта, вы могли бы сделать такую настройку:
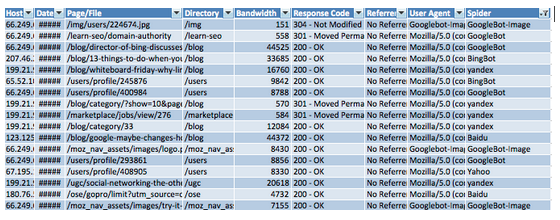
Если остановиться на загруженном в Log Parser файле журналов, то на вкладке «spiders» мы можем увидеть все запросы поисковых ботов и все коды ответов сервера, которые они получили:
На что я ещё обращаю внимание при анализе? Я дополнительно, просматриваю столбцы:
1. Page/File: при обработке каталогов, могут быть некоторые проблемы, поэтому чтобы этого избежать, я разделяю каталоги от файлов. Формула, которую я использую, чтобы сделать это в Excel, выглядит примерно так:
=IF(ISNUMBER(SEARCH("/",C29,2)),MID(C29,(SEARCH("/",C29)),(SEARCH("/",C29,(SEARCH("/",C29)+1)))-(SEARCH("/",C29))),"no directory")
=IF(ISNUMBER(SEARCH("googlebot-image",H29)),"GoogleBot-Image", IF(ISNUMBER(SEARCH("googlebot",H29)),"GoogleBot",IF(ISNUMBER(SEARCH("bing",H29)),"BingBot",IF(ISNUMBER(SEARCH("Yahoo",H29)),"Yahoo", IF(ISNUMBER(SEARCH("yandex",H29)),"yandex",IF(ISNUMBER(SEARCH("baidu",H29)),"Baidu", "other"))))))
Шаг № 3: Стриптиз серверных ошибок кодов ответа
Самый быстрый способ узнать о сложившемся мнении у поисковых систем о нашем сайте, это просмотреть ответы кодов сервера, которые они получили во время парсинга. Слишком много ошибок 404 (страница не найдена) может означать только одно, драгоценные ресурсы сканирования тратятся впустую. Массивный 302 редирект может указывать на тупиковые адреса для ПС в архитектуре сайта. Так, хоть, Google Webmaster Tools предоставляет некоторую информацию о таких ошибках, она не проливает свет на истинное состояние вещей, а вот наши логи не лгут!
Поэтому я строю сравнительную таблицу по всем кодам сервера, которые получили поисковые боты. Для этого я перехожу в раздел «Data>Pivot Table».
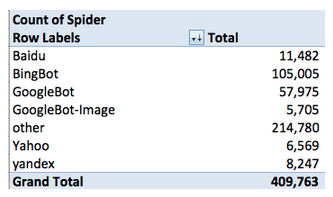
Обычный отчёт, к примеру от того же Австат выглядит так
Как-то не уютно, не так ли? Здесь всё скупо, а главное мы ни видим полной выкладки, что к чему. Только, для себя можем сделать следующий вывод: во-первых, Bingbot гуляет по сайту около 80% от общего числа. Почему? Во-вторых, на "других" ботов приходится почти половина краулинга. Вот и думай, после этого, что мы что-то упустили в наших настройках по User Agent? Ещё львиная доля на краулинг сайта приходится на прочих поисковых ботов – 214780 визитов, эту информацию я не обрабатываю, поэтому исключаю.
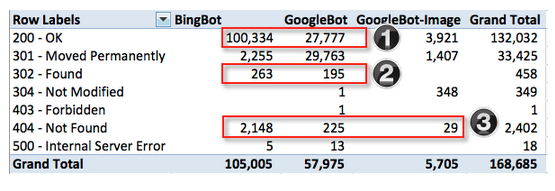
Теперь просмотрим серверные коды ответов в разрезе с ботами:
Здесь я выделила три зоны, которые стоят детального рассмотрения. В целом, соотношение количества к качеству выглядит нормальным, а так как все эти составляющие являются залогом единого общего успеха сайта, то стоит попробовать выяснить, как одно конкатенирует с другим.
1. Почему Bing обошёл Google в два раза?
Установив точную причину, мы можем предпринять меры по устранению возможных негативных факторов, в данной ситуации поразмышлять, почему Google бот не краулит, так глубоко, как Bing и если что-то есть в наших силах изменить в лучшую сторону, то обязательно сделать это.
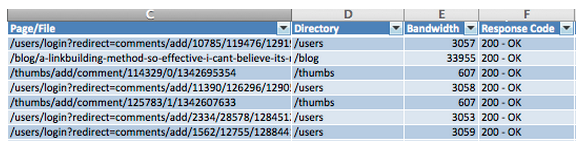
Так просмотрев страницы, которые были успешно отпингованы на (200-OK), то тут мы сразу видим, как Bingbot парсил сайт. Почти 60 000 из 100 000 страниц, которые отскраулил Bingbot, были с редиректов в комментариях пользователей:
Проблема эта для многих известна, если вкратце, получается, что при запросе ссылки в комментарии и JavaScript не включен, то идёт ответ сервера двухсотый, а это ошибка. Учитывая, что почти 60% сканирования Бинга впустую на такие тупики, необходимо блокировать подобный парсинг.
Решение: Добавьте тег - rel = "Nofollow " ко всем комментариям, таким образом мы закроем от индексации комментарии. Получается, что GoogleBot лучше обрабатывает такую ситуацию, чем Bing, поэтому и ложных срабатываний индексации меньше.
2. Количество 302-го кода между Google и Бинг является приемлемым, так как разница не большая. Но и здесь, есть над чем подумать, а именно о том, чтоб 302 использовался только в крайних экстренных случаях, к примеру, когда нет существующей категории в архитектуре сайта и перенаправление пользователей идёт на главную страницу. Так что, если это возможно, то через директивы в robots.txt закройте от индексации эти страницы.
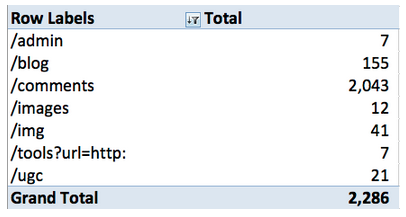
3. Следующее над, чем ещё можно поразмышлять это 404. Благодаря лог-файлам мы очень быстро можем выявить все потенциальные проблемы, которые стоит локализовать. Сделать это можно при помощи сортировке 404-й по каталогам, так мы в итоге увидим сводную таблицу:
Самое проблемное место на сайте, которое составляет 90% от общего числа 404-х сгруппирована в директории – комментарии. Для нас это уже не новость, так как в первом пункте мы не только выявили это проблемное место, но и нашли решение проблемы с комментированием на сайте. И приятно то, что нофоллоу прикрывает 404-е.
Заключение
Google и Bing Webmaster инструменты предоставляют информацию о сканированных ошибках, но во многих случаях они ограничивают конечные данные. Мы в свою очередь, как профи должны, использовать все источники данных, которые доступны, в конце концов.
Это ещё не конец, это только начало…
Успехов вам.
|
|
|
 |

|
Здесь присутствуют: 1 (пользователей: 0, гостей: 1)
|
|
|
|