|
|
Как сделать поиск по статическому сайту
|
 |
14.06.2014, 17:46
|
|
#1
|
|
Регистрация: 03.03.2013
Сообщений: 127
|
| Как сделать поиск по статическому сайту
|
Хостинг статических блогов, типа GitHub Pages является чрезвычайно популярным способом легкого создания блогов на уровне полномасштабных CMS. Вторая ситуация, более популярная у присутствующих вебмастеров – сграбленный из вебархива сайт, который по определению не может быть динамическим. Одним из основных недостатков таких сайтов является то, что отсутствует простой и надежный способ обеспечения функционального поиска.
К счастью, с помощью пары бесплатных инструментов, вы можете легко создать динамический поиск для своего статического сайта. Давайте рассмотрим пошаговое создание такого поиска.
Шаг 1: Crawl
Во-первых, вам нужно будет использовать сервис Crawler import.io, чтобы захватить все содержимое вашего сайта, и создать индекс, а затем по нему искать.
У них на сайте размещены уроки, которые познакомят вас созданием Crawler, если вы никогда раньше о нем не слышали.
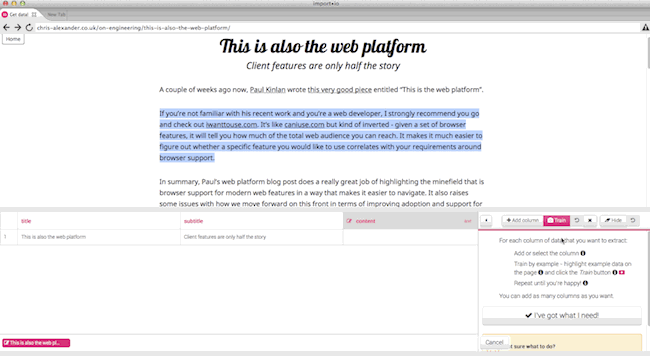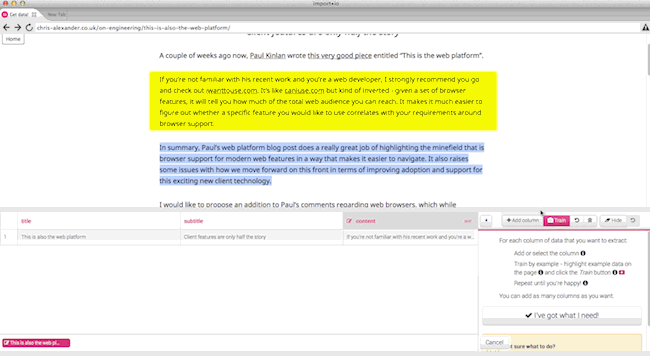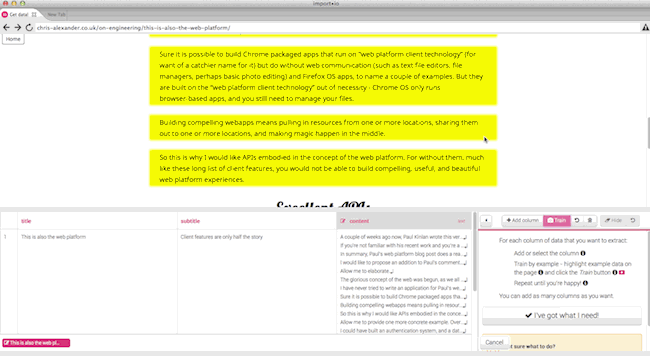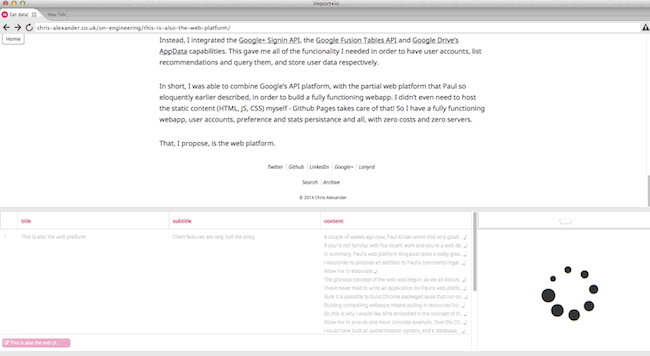
Когда вы создали Crawler под свой блог, вы можете создать столбцы для " title" и "subtitle", по которых будет идти поиск; или вы можете забрать все содержимое, используя колонки “images” (type IMAGE), “content” (type STRING) и “links” (type LINK), которые будут отображать все изображения, текст и ссылки на странице.
В то же время вы можете обучать только один столбец, и забрать лишь несколько абзацев:
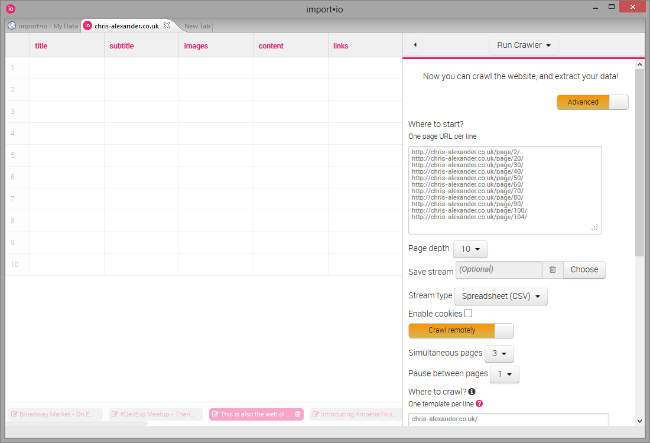
Пару советов: во-первых, обучите более 5 необходимых страниц - я обучил более 10, чтобы убедиться что охватил все форматы постов. Кроме того, когда вы используете свой crawler, убедитесь, что даете ему достаточно стартовых страниц, с которых он сможет обойти все ваши посты. Дело в том, что по умолчанию он будет следовать только 10 по первых ссылкам страницы, и чтоб обойти все, вам, возможно придется увеличить это число.
Вот пример конфигурации сканирования моего блога:
Шаг 2: Поиск провайдера для индекса
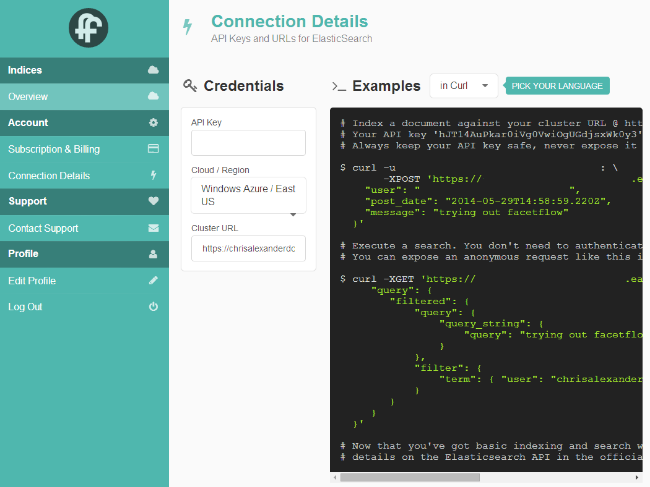
В поисках быстрого способа провести поисковый индекс своего блога, я решил попробовать FacetFlow: мало того, что они используют индексы Elasticsearch, так они имеют еще и неплохую песочницу, которая позволяет хранить до 5000 документ или до 500MB данных.
После того, как вы зарегистрировались, они покажут параметры соединения с сервисом:
Шаг 3: Создание индекса
Для того, чтобы помочь вам создать индекс с нужными параметрами, я написал несколько утилит на Python.
Скопируйте репозиторий на свой компьютер, а затем настройте под свои Facetflow данные: скопируйте файл "es.json.template" в "es.json", и внесите свои данные. Вам нужно будет изменить "host", и внести свой Facetflow API ключ в поле "credentials: username".
Я создал основное отображение индекса Elasticsearch в "index_mapping.json" - вы можете изменить его, если хотите, или можете оставить все как есть.
Как только эти два файла готовы, вам просто нужно запустить сценарий "create_index.py". Этот сценарий будет создать соответствующий индекс в Facetflow аккаунте.
(Так же там есть "delete_index.py" - скрипт, который будет удалять индекс и данные, если вам такое понадобиться)
Шаг 4: Индексация содержимого
Теперь, когда мы создали наш сканер и наш поисковый индекс готов к данным, пришло время для запуска Crawler и заполнению нашего индекса контентом для поиска.
Есть несколько конфигурационных файлов, которые нужно настроить для этой цели.
Во-первых, настройка import.io - копируем "auth.json.template" в "auth.json", а затем вносим в него свой GUID пользователя и API ключ аккаунта.
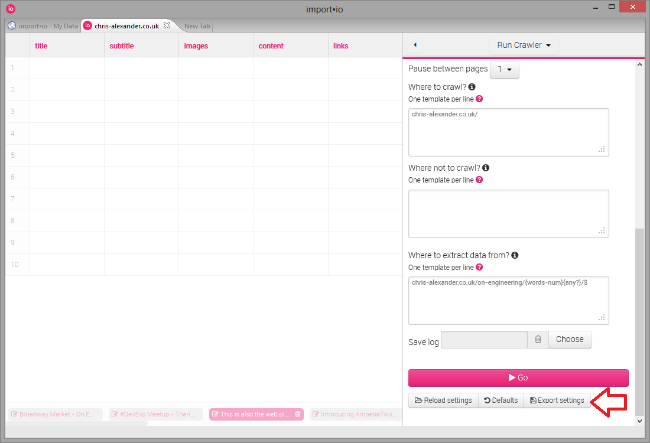
Далее, вам нужно создать конфигурацию сканирования. Пример этой настройки в "crawl.json.example", но это пример для сканирования моего блога - вы можете получить файл "crawl.json" для собственного краулинга, открыв инструмент import.io, и выбрав там Export settings:
Окончательный файл конфигурации создается на базе "mapping.json.template" - если вы использовали те же имена столбцов, что я изложил выше, вы можете просто скопировать этот файл в "mapping.json". Если у вас немного другие имена столбцов, то можете изменить этот файл в соответствии с названием столбцов.
Итак, если у вас есть auth.json, crawl.json, es.json, index_mapping.json и mapping.json, значит все готово к запуску краулера и помещения данных индекса Elasticsearch на Facetflow.
Первым делом, вам нужно запустить сценарий Python - "Server.py". Он просматривает страницы с данными, которые находит краулер import.io, и затем отправляет их в Facetflow.
После этого запускаете import.io краулер. Для запуска командной строки на сервисе есть расширенная инструкция.
После того, как искатель запущен, он покажет вам страницы данных в командной строке. Это будут строки созданные скриптом, который информирует вас о том, как он обрабатывает их и отправляет в индекс Elasticsearch.
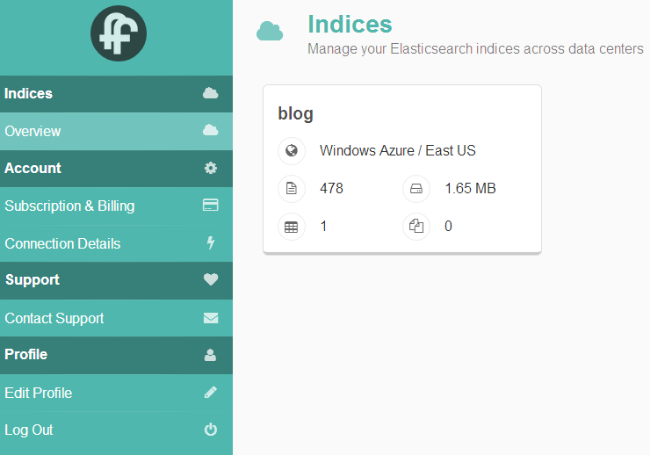
По завершению этого процесса, краулер import.io выведет сообщение " Crawl finished ", а затем выйдет - теперь вы можете остановить Python сценарий (Ctrl + C). Facetflow должен показать ваши посты в панели управления:
Всякий раз, когда вам нужно повторно индексировать свой контент (например, вы редактировали сообщения в блоге или создали новые) можно повторить два последних шага. Поскольку цикл использует URL страницы в качестве ID, обновления будут обработаны правильно и все новые изменения переиндексируются корректно. Можно даже запустить его в качестве запланированной задачи сервера, для того чтобы автоматически обновлять индекс.
Шаг 5: Поиск содержимого
Теперь, когда у вас есть индексированный контент, пришло время найти его! Facetflow показывает вам некоторые примеры как это сделать, но если вы хотите в полной мере использовать силу Elasticsearch, используйте поисковый URL типа:
ваш_аккаунт_.facetflow.io/blog/post/_search?q=поисковый запрос&df=heading&df=content&from=20&size=10
Этот пример индекса показывает, как объединить поисковый запрос "q", полей в которых искать (в примере это заголовок и содержание df=heading&df=content), и нумерацию страниц от Elasticsearch’s query API, чтобы получить результат.
После этого, вы можете обернуть строку в JavaScript сценарий, и превратить его в полномасштабный поисковый инструмент своего сайта. Вот как это выглядит на моем сайте:
|
|
|
|
|
14.06.2014, 18:37
|
|
#2
|
|
Регистрация: 11.02.2012
Сообщений: 2,241
|
Сообщение от Holly
сграбленный из вебархива сайт, который по определению не может быть динамическим
| Это как? Чето я не допонял? Что, чем и как вы Грабите?

|
|
|
|
|
23.06.2014, 16:18
|
|
#4
|
|
Регистрация: 23.02.2014
Сообщений: 2
|
Класс Спасибо
|
|
|
 |

|
Здесь присутствуют: 1 (пользователей: 0, гостей: 1)
|
|
|
|