|
|
Подсекаем Googlebot журналами серверов - часть 2
|
 |
08.08.2013, 16:24
|
|
#1
|
|
Регистрация: 02.07.2012
Сообщений: 648
|
| Подсекаем Googlebot журналами серверов - часть 2
|
Добрый день.
Продолжим с вами тему логов серверов. Конкретно, заострим внимание на актуальной теме, как сделать так, чтоб наш сайт был максимально соблазнительным для Googlebot-а? Все, кто знает ответ, не спешите с выводами, вдруг то, что вы прочитаете вас приятно удивит. Итак, макарену танцевать не будем, все, как и в первой статье - Почему поисковые боты ненавидят логи веб-серверов, будем брать из реальности.
Обычно, чтобы знать в лицо своего оппонента, о нём собирают информацию и тут все методы хороши: частные детективы, жучки, скрытые камеры, взлом персональных данных и т.д. Но нам с вами, ни чего из этого не понадобится, так как у нас всё уже есть, по простой причине – наш оппонент, сам конкретно наследил. Смотрим.
Робот Google, как обычно сканирует наш сайт. При сканировании он старается, выполнить три основных задачи. Первая, какие страницы надо прочесать, это определяется наличием новых обратных ссылок, которые явно указывают на страницы сайта, которые жаждут, чтоб их посетил гуглбот, тут ещё стоит добавить внутреннюю перелинковку, по которой гуглбот тоже не прочь пройтись, как по Бродвею, а берёт он эти линки из тщательно подготовленной карты сайта.
Далее, робот Google определив, сколько точно страниц, подлежит сканированию, просчитывает примерное время загрузки, общую производительность, а также выявляет циклические линки, которые надо занопить, чтобы не было бессмысленных бесконечных итераций.
На последнем шаге сканирования Googlebot определяет такой фактор, как часты обновления сайта и когда примерно стоит вновь вернутся для новой индексации.
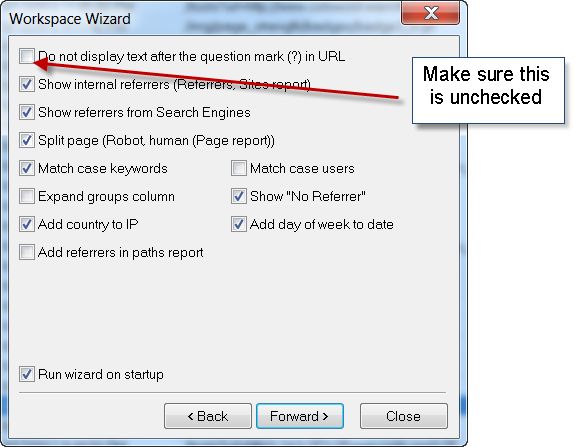
Держа в памяти эти шаги Гуглбота, давайте взглянем на то, так ли это на самом деле. Как получить лог с сервера в нужном формате я уже подробно расписала в первой статье, если не помните или не читали, можете сейчас это сделать, так чтоб в дальнейшем было меньше вопросов. Итак, перепроверьте такие ли выставлены у вас опции в настройках для логирования и импорта файла журнала:
Первое, что мы хотим, просмотреть это то, где на сайте Googlebot больше всего тратит свое время для парсинга наших ресурсов? Поэтому, надо сделать маленькую зачистку для того, чтоб файл журнала был готов к дальнейшему экспорту. В сохранённом CSV-файле сделаем небольшое форматирование и очистку от лишних данных:
1. Сохраняем файл с расширением Excel, например в «. XLSX» - формате
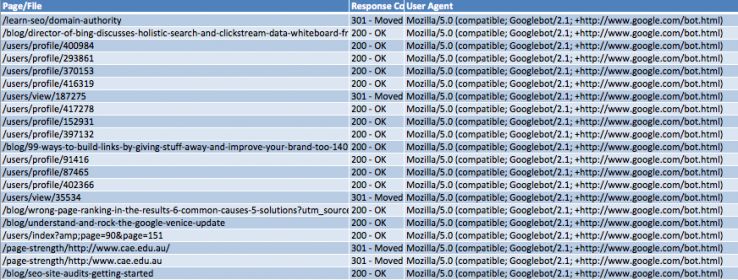
2. Удаляем в этом файле все столбцы, за исключением первых трёх столбцов: Page/File, Response Code и User Agent, в итоге вы должны получить такой вид журнала:
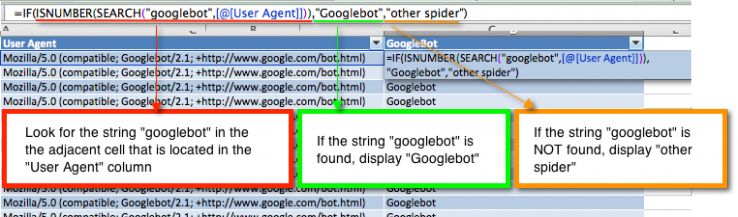
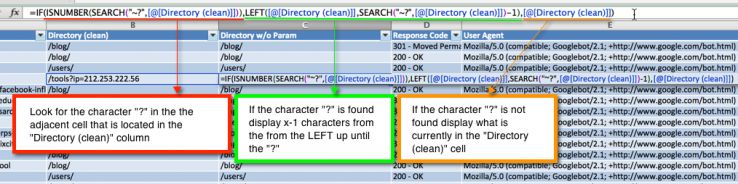
3. На этом шаге мы локализуем Googlebot от других поисковых пауков, создав новую колонку и задав для неё следующую формулу, которая сортирует "Googlebot" в ячейках 3-его столбца:
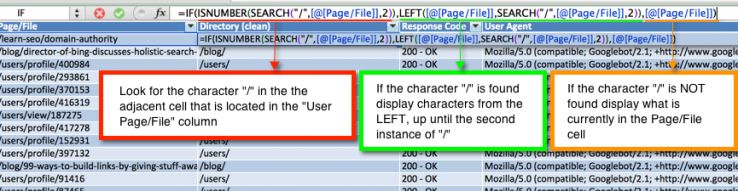
4. Теперь в колонке Page/File нам надо обрезать домены слева, а также справа другую часть адреса, так чтоб выделить верхнюю директорию и полученный результат скопировать в новый столбец, который так и назовём – Directory, всё это для того, чтоб наглядно видеть частоту просмотров той или иной директории сайта:
5. На этом шаге мы ещё с вами поколдуем и в этом нам поможет книга чародеев Excel. Да, да мы не закрываем наш уже достаточно преобразованный отчёт, а всё ещё продолжаем кудесничать. Конкретно, мы задействуем такой параметр в Excel, как вопросительный знак - "?", но не просто знак вопроса, который по умолчанию в Excel используется для поиска чего-то, а дополнительно пропишем перед знаком вопроса символ тильды - "~" и всё вместе у нас получится такого вида – “~?”, этим мы хотим указать, что вопросительный знак мы будем использовать в качестве символа подстановки. Полный вариант формулы показан на скрине в строке формул(fx):
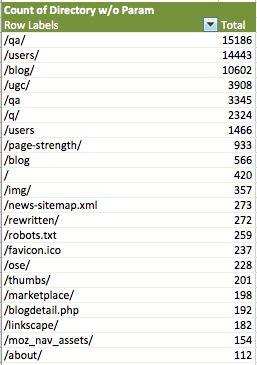
6. Всё, мы сделали это! Конечные данные, которые мы так долго сортировали, теперь красиво структурированы для визуального анализа (в левом столбце корневые директории сайта, а в правом столбце общее количество запросов Googlebot, который отправлял поисковый паук в день индексирования сайта):
Теперь стоит ответить на ключевой вопрос – насколько объективны данные, которые собрал на сайте поисковый паук? Для ответа на этот вопрос стоит детально проанализировать несколько различных областей данных в итоговом отчёте:
• Более 70% своего бюджета сканирования Google фокусируется на трёх секциях, в то время как более 50% идет на папки /qa/ и /Users/. Соответственно, надо заострить дополнительно внимание в Google Analytics для определения точного количества трафика в эти разделы с органического поиска. Если показатели будут низки, то обязательно надо пересмотреть вопрос оптимизации этих разделов в ближайшее время.
• Вот, другой случай, когда директория /page-strength/, используемая для внутренних целей сайта и которая вообще не нуждается в индексации была запрошена почти 1000 раз. Скорей всего это случилось при индексации из-за наличия внешних ссылок, указывающих на эту секцию. Чтобы избежать дальнейших итераций запросов Гуглботом к этой директории, надо принудительно через файл robots.txt соответствующими директивами наглухо закрыть от индексации эту папку.
• Если на верхнем скрине мы видим топовые позиции по запросам, то не пренебрегайте и теми каталогами и разделами, которые расположены в минимальном спектре запросов для аналитики, ведь их тоже посещают поисковые краулеры:
Вот и первая неприятность, каталог /webinars, который должен быть в топах, на самом деле обделён и не получает достаточного внимания Google ботом.
Это лишь несколько примеров того, как можно выявить узкие места на сайте при помощи логов сервера. И для самостоятельного анализа своих логов, ну и для закрепления материала, я бы вам рекомендовал, проработать дополнительные вопросы:
• Краулеры запрашивают страницы, которые закрыты от индексирования в robots.txt?
• Постарайтесь определить разделы сайта, которые перегружены запросами?
В качестве бонуса, я сделал screencast по анализу сканирования Googlebot, как говориться лучше один раз увидеть, чем сто раз услышать:
http://fast.wistia.net/embed/iframe/qnkuo8djk9
В моем следующем посте по анализу лог-файлов, я объясню более подробно, как определить дублированный контент и выявить прогнозируемые тенденции с течением времени.
Продолжение следует.
|
|
|
 |

|
Здесь присутствуют: 1 (пользователей: 0, гостей: 1)
|
|
|
|