|
|
Поговорим о сателлитах - часть 2. Готовим контент.
|
 |
12.06.2013, 00:51
|
|
#1
|
|
Регистрация: 08.05.2013
Сообщений: 57
|
| Поговорим о сателлитах - часть 2. Готовим контент.
|
И снова здравствуйте!
Сегодняшняя статья будет продолжением первой части http://rebill.me/showthread.php?t=1982 , где мы узнали что такое сателлиты, как их использовать и даже установили на хостинг граббер бесплатного контента "Випбабло" Остановились мы на том, что начали парсинг одного из выбранных ресурсов. Я хотел бы немного рассказать о том, как упростить работу с контентом, не загружая статьи, которые вряд ли подойдут для изготовления сателлитов. В этом нам помогут более тонкие настройки парсинга при создании нового проекта.
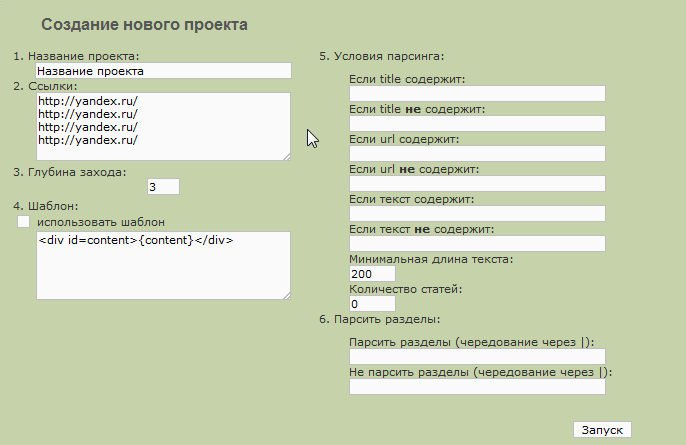
Пробежимся по полям в которых мы можем что то поменять:
В левой части настроек что либо менять не требуется, исключая пункт "Глубина захода" Многие сайты имеют большой уровень вложенности страниц, и если вы видите что на выбранном доноре именно такая структура, то можно значение "3" поменять на большее, хотя в большинстве случаем хватает и выставленного по умолчанию.
Перейдем к правой части настроек, именно они могут повлиять на количество мусорных статей, которые соберет граббер.
5. Условия парсинга:
Поле "Если title содержит:" Позволяет выбрать статьи, которые в заголовке содержат какое либо слово. То есть граббер будет сохранять только те статьи, в которых содержится указанное в этом поле слово.
Поле "Если title не содержит:" Назначение этого поля обратно предыдущему. В нем можно задать слова, которые вы не хотели бы видеть в заголовках будущих материалов.
Поле "Если url содержит:" В этом поле указываются уже не слова, а символы в урлах статей, которые нужны вам
Поле "Если url не содержит:" Опять же оно обратно предыдущему. К примеру на выбранном вами сайте кроме статей есть еще и форум. Вряд ли форумные посты в одно - два предложения нас устроят в качестве самостоятельной статьи. Остается посмотреть как выглядит урл этого форума. Если он выглядит как "site.ru/forum/thread.php?t=82" то исключить форумные посты в статьях можно введя в это поле значение "forum".
Поле "Если текст содержит:" В нем мы можем выбрать статьи, которые в своем теле содержат нужные вам слова.
Поле "Если текст не содержит:" Опять же обратно предыдущему. Например на сайте есть статьи, в которых содержится просьба отправить смс на платный номер. (первое что пришло в голову  ) То есть введя в это поле значение "отправьте смс" мы не получим статей, содержащих такое предложение. ) То есть введя в это поле значение "отправьте смс" мы не получим статей, содержащих такое предложение.
Поле "Минимальная длина текста:" По задумке автора софта значение этого поля могло бы запретить грабберу собирать статьи с меньшим количеством символов, чем указано. Но к сожалению на практике эта настройка чаще всего не работает. Граббер собирает и маленькие статьи.
6. Парсить разделы:
Поле "Парсить разделы (чередование через |):" Многие новостные сайты публикуют материалы разных тематик. Если мы собираем лишь определенную тематику, то это поле поможет исключить нетематические статьи. Для этого достаточно посмотреть как выглядит урл нужных статей. Если например он выглядит как "site.ru/articles/autonews/page1.php", то указав в поле значение "autonews" получим статьи только из этого раздела.
Поле "Не парсить разделы (чередование через |):" И в этом случае назначение этого поля обратно предыдущему. Введя в него значение из урла какой либо категории сайта - донора, мы не получим материалы которые содержатся в этой категории.
С тонкими настройками при создании проекта мы закончили. Перейдем теперь к самому извлечению напарсенных статей.
Что бы было проще, для примера я выбрал не такой большой ресурс как в первой части. Как видим со всего сайта граббер собрал мне около 350 статей. Парсинг закончен, когда в графе "Страниц обрабатывается" будет значение "0" Перейдем по ссылке из названия проекта.
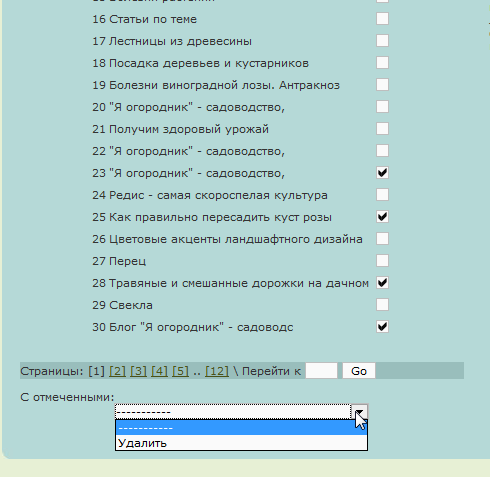
Здесь мы можем пощелкав в левой части интерфейса по названиям статей посмотреть сами статьи, удалить мусорные, Для этого надо поставить рядом с заголовком галочку в нужных чекбоксах и выбрать нужное действие.
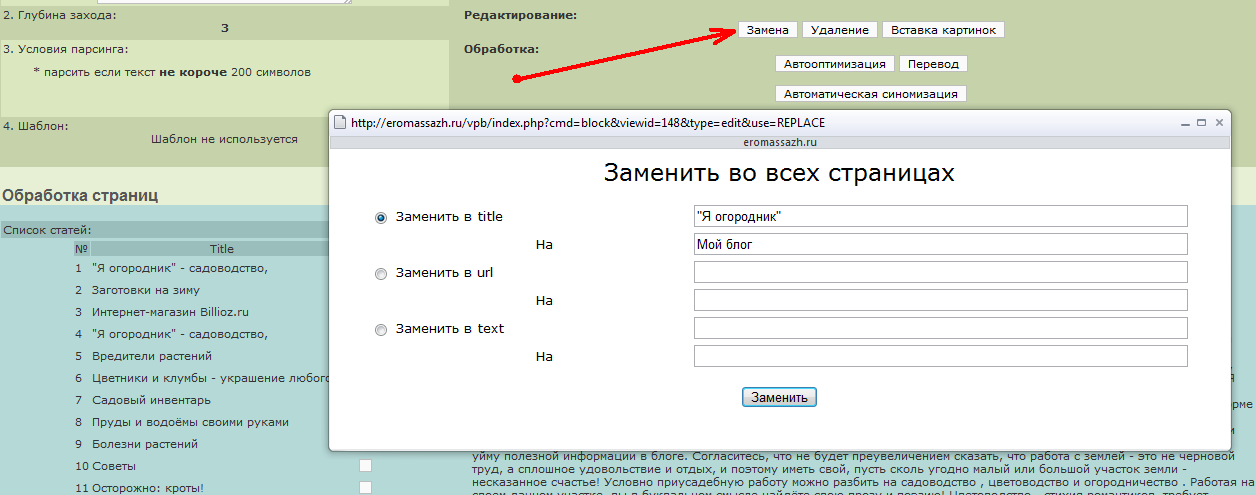
Также мы можем массово отредактировать как заголовки, так и какие либо слова в теле статей.
К примеру многие сайты добавляют к заголовку статьи урл своего сайта. Этим инструментом мы можем как просто убрать чужой урл из заголовка, так и поменять его на свой. В граббере есть инструмент для парсинга тематических картинок и вставки их в статью, но этой возможностью я не пользуюсь, так как при такой автоматизации получается слишком много дублей изображений. Для этого есть сторонние инструменты, о которых я могу рассказать если будет такая потребность.
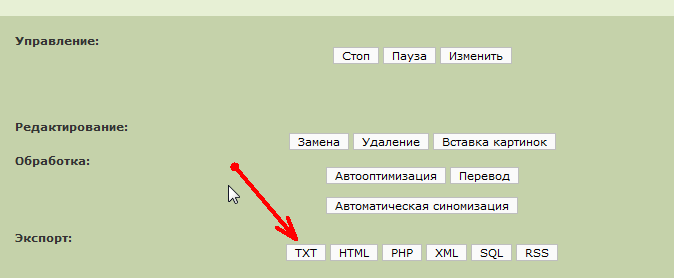
Дело осталось за малым, нам нужно сохранить полученные статьи. для этого смело жмем кнопку "TXT"
Сохранить их надо в отдельные файлы, для чего нужно повторить настройки из скриншота:
Собственно изменить нужно только галку в пункте "В отдельные файлы" Все остальные настройки можно оставить по умолчанию. Осталось нажать кнопку "Экспорт" и скачать заархивированный файл с нашими статьями. Каждая статья сохраняется в отдельный файл. Из них мы и будем делать сателлиты.
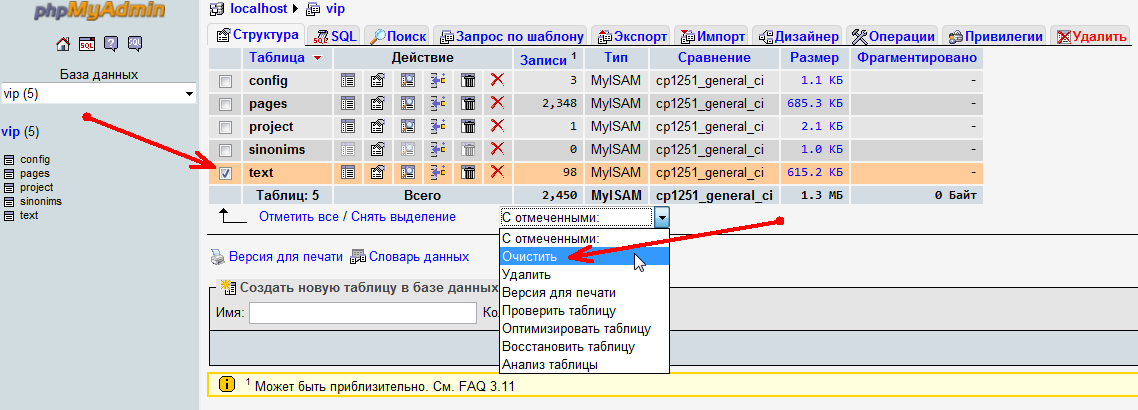
Стоит упомянуть еще один момент. Если вы выбрали в качестве донора очень большой сайт, то не стоит ждать пока граббер соберет все что есть. Не знаю от чего это зависит, но если количество статей превысит 10000, то при нажатии на кнопку "TXT" мы можем увидить пустую страницу. Чтобы это предотвратить, можно экспортировать статьи прямо во время парсинга. На работу граббера это никак не повлияет. После экспорта части статей, нужно очистить таблицу "text" в базе данных граббера. Для этого перейдем в PhpMyAdmin (туда, где мы создавали базу данных при установке софта на хостинг) В левой части страницы нужно кликнуть по названию нашей базы данных и сделать несложную манипуляцию: Ставим галку на таблице "text" и выбираем действие "Очистить"
Обращу еще раз ваше внимание, таблицу надо не удалить, а именно очистить.
После очистки таблицы парсинг продолжится далее. Останется иногда контролировать число в графе "Страниц получено" на странице списка проектов. При достижении значения близкого к 10000 стоит снова экспортировать статьи и еще раз очистить таблицу базы данных. Я не дожидаюсь когда их количество становится слишком большим, и начинаю экспорт уже при наличии 5-6 тыс. статей.
В заключении этой статьи хотелось напомнить, что не стоит делать сателлит из материалов только одного сайта, который любезно позволил спарсить себя. Поставьте себя на место поисковых систем: вы видите сайт - с точной копией материалов другого. Само собой, что вряд ли такие сателлиты даже войдут в индекс. Скорее всего они попадут под фильтр, в результате чего получим испорченный домен и потраченное зря время. Наилучшим решением для этого будет использование для одного сателлита материалы десятков сайтов - доноров. В таком случае появляется некоторая уникальность копипастного сайта (каламбурчик  ) На этом пожалуй и закончу вторую часть рассказа об изготовлении сателлитов. ) На этом пожалуй и закончу вторую часть рассказа об изготовлении сателлитов.
|
|
|
 |

|
Здесь присутствуют: 1 (пользователей: 0, гостей: 1)
|
|
|
|