|
Регистрация: 30.07.2014
Сообщений: 474
|
| Как Google изменяет запросы: результаты для SEO
|
В новелле Франца Кафки «Превращение» человек просыпается однажды утром и обнаруживает, что превратился в гигантское насекомое. Если ключевые слова были бы экзистенциалистами, они могли испытывать что-то подобное, так как после того, как их вводят в строку поиска Google, они проходят через множество преобразований, чтобы стать новой, модифицированной версией самих себя — запросами, которые по мнению Google лучше отражают намерение пользователя.
Чтобы проиллюстрировать то, о чем я говорю, позвольте мне попросить вас о небольшом одолжении. Зайдите в Google и введите в строку поиска «Oscar». Нет, серьезно, сделайте это.
Скорее всего, все результаты в ТОП-е связаны с 89-й церемонией вручения наград Академии, которая состоялась несколько дней назад. В некоторых результатах, скорее всего, слово «Oscar» не упоминается совсем (это единственное слово, которое вы ввели, помните?). Каким-то образом Google знает, что вы ищете информацию о конкретной церемонии, а не общую информацию о церемонии Оскар, сведения об имени Оскар или что-нибудь еще, незримо превращая ваш запрос в то, что с трудом напоминает оригинал.
В этом посте я рассмотрю то, как этот процесс может работать, и что это означает для сеошников.
Ассоциации, релевантность и объем поиска
Недавний патент Google о предоставлении уточнений по поисковым запросам позволяет понять, как Google может обрабатывать поисковые ситуации, которые являются неоднозначными, слишком общими, слишком «узкими» или в них отсутствует контекст (например, как в случае с запросом «Oscar»). Патент описывает систему трансформации запроса в лучше сформулированную его версию, так что Google сможет предоставить именно те результаты, которые хочет получить пользователь.
Согласно патенту, когда Google получает запрос, он начинает искать веб-документы в индексе, которые он связывает с запросом на основе тех ключевых слов, которые ввел пользователь. Затем он анализирует выбранные страницы и понятия или семантические кластеры, с которыми они ассоциируются. Если он понимает, что результаты поиска относятся к совершенно другим понятиям, он, скорее всего, сделает вывод о том, что запрос является неоднозначным и нуждается в уточнении.
Давайте посмотрим, как работает процесс поиска уточнений на примере запроса «Oscar». Когда вы введете в поиске запрос «Oscar», Google начнет собирать определенное количество результатов поиска, которые буквально соответствуют запросу. Для данного примера, скажем, это число 100. Каждому из 100 найденных результатов присваивается балл, оценивающий их релевантность исходному запросу («Oscar»), вероятно, на основе внешних и внутренних SEO факторов.
Далее Google выявит темы или семантические кластеры, которым принадлежат эти страницы; для запроса «Oscar» это может быть «Премия Американской киноакадемии», «Имя Оскар», «Рыба Оскар» и, возможно, несколько более мелких кластеров. Так или иначе, Google должен выяснить, какое из этих понятий вас интересует, и с этого места все становится очень интересно.
Согласно патенту далее Google обращается к «базе ассоциаций», месту, где он хранит последние запросы, веб-страницы и ассоциации между ними. Каждой ассоциации Google присваивает вес, степень релевантности страницы запросу, умноженной на частоту запроса или объем поиска.
Далее Google может найти топовые результаты, которые он подобрал для запроса «Oscar» в этой базе. Он будет смотреть на прошлые запросы, связанные с каждым из результатов, и веса этих ассоциаций. Ассоциации с наибольшим баллом, принадлежащие кластерам с наивысшей оценкой, будут выбраны в качестве кандидатов для уточнения запроса.
Помня о том, что вес - это степень релевантности, умноженная на объем поиска, вы, скорее всего, начнете понимать, почему в данный конкретный момент на запрос «Oscar» поисковая система выдала нечто вроде «Academy Awards ceremony 2017».
Стоит отметить, что Google часто выбирает более одного кластера или темы для уточнения запроса. Это особенно заметно, когда возможные кластеры, ассоциирующиеся с первоначальным ключевым словом, имеют равные или близкие к равным веса, что происходит, когда Google позволяет вам решать, какие темы вас больше интересуют.
Контекст
Еще один патент проливает свет на роль контекста в уточнении запросов пользователя. Контекст в данном случае это набор слов и фраз, связанных с единственным доменом. Данные для подобных «контекстов» получаются из больших корпусов учебных материалов, а затем, вероятно, улучшаются и расширяются с помощью машинного обучения. Эти контексты помогают Google как индексировать информацию, так и лучше обслуживать поисковые запросы.
В первом случае Google делит «вселенную коммуникации» («the universe of communications») на домены, которые схожи с кластерами, обсуждаемыми выше. Анализируя веб-страницу, а также слова и выражения, используемые в рамках ее, Google может легко выяснить, к какому контексту можно отнести данную страницу, основываясь на пересечении слов в определенном контексте и контенте на странице. Поэтому, когда он посмотрит на страницу, которая содержит такие ключевые слова, как «Американская академия», Премия «Оскар» и «лучший кинофильм», он решит: «Ага, контекст данной страницы связан с премией «Оскар»».
Со стороны пользователей, чтобы определить контекст их запросов, Google будет смотреть на такие вещи, как непосредственные истории поисковых запросов пользователя и, если необходимо, будет анализировать полностью их историю поиска.
Другими словами, если история поиска указывает на то, что вы особенно интересуетесь глазчатым астронотусом, Google может задействовать кластер, связанный с данной рабой, когда вы будете вводить запрос «Oscar», опять же основываясь на контекстуальной информации, которая у него имеется о вас, как о пользователе. Таким образом, поисковый запрос «Oscar» превращается в просьбу: «Google, пожалуйста, проведи поиск результатов по запросу «Oscar», принимая во внимание все, что ты знаешь обо мне».
Контекст 2.0
История поиска и загруженных страниц – это не единственный вид «контекста», который Google может использовать для уточнения запросов. Ряд недавних патентов подтверждают, что более сложная детальная информация о пользователе такая, как просмотренные фильмы или прослушанная музыка, может быть использована для уточнения запросов и выводимых результатов поиска. Контекст в режиме реального времени такой, как, например, фильм, который в настоящее время просматривается, может быть также использован, когда пользователь делает голосовой запрос.
Например, пользователь может ввести запрос на мобильном устройстве в разговорном стиле: «Когда я видел этого актера раньше?» при просмотре определенного контента, например, фильма «Социальная сеть».
В соответствии с этими патентами, Google может также следить за тем, что показывают по телевизору в вашем регионе, и искать запросы, которые могут быть связаны с этой информацией. Поэтому, если вы осуществляете поиск по запросу «социальная сеть», и фильм «Социальная сеть» в настоящее время идет в вашем регионе, это может повлиять на результаты поиска, которые вы получите.
Например, это может способствовать тому, что предпочтение будет отдано кластеру, связанному с фильмом «Социальная сеть», а не другим семантическим кластерам, ассоциирующимся с запросом.
Местоположение
Расположение, конечно, является типом контекста, но оно заслуживает собственное место в этом списке. Местоположение уже влияет на большую часть запросов, а это особенно важно для компаний, которые пытаются сделать так, чтобы их сайты ранжировались локально. Но использование Google местоположения для уточнения запросов в ближайшее время может уйти далеко за пределы текущего положения дел.
Вы, наверное, уже знаете, что если вы вводите запрос «Starbucks», «Walmart» или название какой-либо другой компании, что может означать, что вы заинтересованы в физическом местоположении данного бизнеса, Google будет показывать вам локальные результаты поиска и настроит органическую выдачу так, чтобы помочь найти физическое место, которое вы, (скорее всего) ищите.
Это можно развить, так как Google может анализировать паттерны запросов и связывать их с компаниями, которые находятся близко к местоположению того, кто осуществляет поиск. Итак, если вы спрашивали у Google: «В какое время открывается Starbucks?» или даже, «Как называется этот парк?», в то время как объект, о котором идет речь, находится четко поблизости от вас, Google сможет дать вам ответ.
Так что в следующий раз, когда вы будете проходить мимо ресторана, скажем, под названием «Zio Pepe» и вам станет интересно, насколько он хорош, попробуйте попросить Google «показать рейтинг данного заведения». Данный запрос может быть превращен в нечто вроде «zio pepe ratings», и вам не придется беспокоиться о том, как правильно произносится «zio» по-итальянски.
Например, пользователь, который не говорит по-немецки, может находиться на отдыхе в Цюрихе в Швейцарии и может сделать запрос [часы работы], стоя рядом с рестораном «Zeughauskeller», чье название является трудным для произношения и/или написания. В качестве другого примера внедрение данного изобретения позволит пользователям более удобно и естественно взаимодействовать с поисковой системой (например, отправлять запрос [показать блюда на обед] вместо запроса [обеденное меню ресторана «Fino Ristorante & Bar»].
Замена запроса
Другой недавний патент, зарегистрированный компанией Google, фокусируется на замещающих выражениях и синонимах для уточнения запроса. Данный процесс включает выявление концепции в запросе пользователя и выяснение, может ли эта же концепция быть сформулирована по-другому (без искажения смысла запроса), чтобы обеспечить более подходящие результаты поиска.
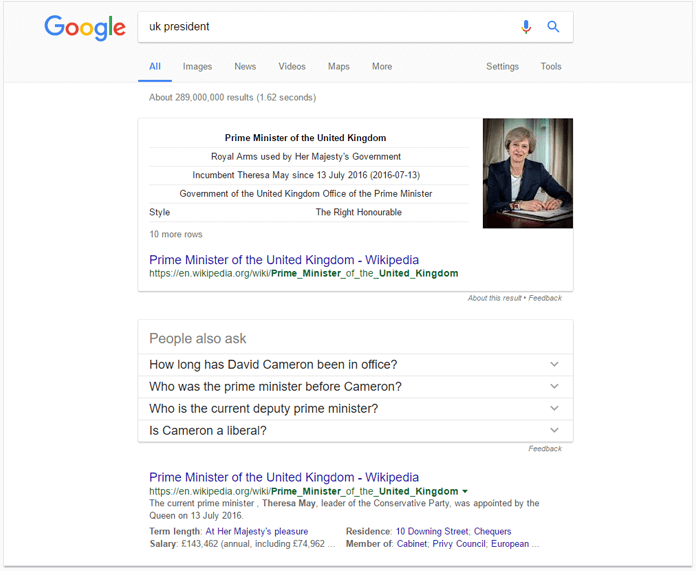
Чтобы увидеть, как это работает, давайте осуществим поиск по запросу «UK President». Если бы Google использовал для подбора результатов лишь два слова, упомянутые в запросе «UK» и «President», результаты могли бы включать статьи о президентах других стран, приезжающих в Великобританию. Вместо этого, Google определяет, что пользователь, скорее всего, ищет информацию другого рода, а слово «President» в действительности является ошибкой того, кто осуществляет поиск, когда на самом деле подразумевалось выражение «Prime Minister».
В данном контексте выражение «Prime Minister» является синонимом «President», что в сочетании с «UK» также представляет собой известный объект. Все это делает данное выражение подходящей заменой исходного запроса.
(Обратите внимание, как Google выделил жирным шрифтом фразу «Prime Minister» в URL-адресе в поисковой выдаче, и как слово «President» появляется ниоткуда среди первых результатов).
Технология Word2Vec
За последнее время в SEO-пространстве было много обсуждений технологии Word2Vec, вызванных мнениями многочисленных сеошников о том, что она используется алгоритмом RankBrain. И это мнение имеет свои основания: многие специалисты, работавшие над RankBrain, также разрабатывали и Word2Vec, и многие описания этих двух проектов почти идентичны.
Инструмент Word2Vec получает в качестве входных данных определенный объем текста и выдает компактные векторные представления слов. Сначала он создает словарь из учебных текстовых данных, а затем усваивает векторное представление слов. Полученный файл с векторным представлением слов может быть использован как для обработки естественного языка, так и для приложений, в которых задействовано машинное обучение.
Прежде чем мы перейдем к плюсам и минусам технологии Word2Vec, давайте оговорим одну вещь. В последнее время много говорилось о векторах запросов и векторном пространстве. Хотя эти понятия могут казаться сложными в теории и звучать так, как будто вам нужно пройти курс матанализа, чтобы понять их, их индивидуальные визуализации на самом деле удивительно понятны.
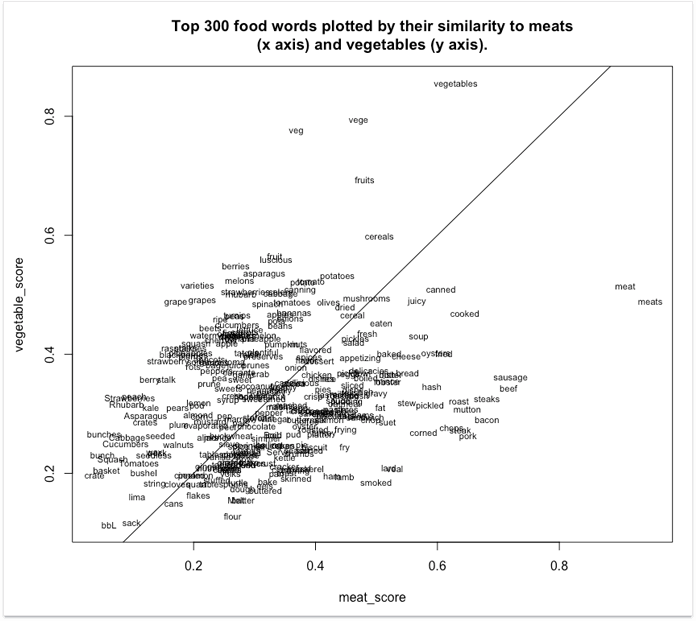
Давайте рассмотрим простой пример. Скажем, у вас есть набор запросов, которые нужно разбить на две группы: «овощи» и «мясо». Не все слова являются названиями овощей или видов мяса, но вы должны это сделать в любом случае, помещая слова, которые чаще встречаются в контексте мяса (например, «копченый») в кластер «мясо», и наоборот.
Вот как может выглядеть визуализация вектора таких слов.
Как видите, запросы с высоким «овощным» баллом располагаются ближе к верху системы координат, а слова с высокой «мясной» оценкой ближе к правому краю. Ближе к средней линии располагаются более нейтральные слова, те, которые часто встречаются в обоих контекстах. Важно отметить, что кластеризация поисковых запросов на семантические группы - это далеко не единственное, что может делать Word2Vec.
Другим важным аспектом является выявление взаимосвязи между поисковыми запросами путем вычисления расстояния между векторами. Выше вы можете заметить, что слова «meat» и «meats» расположены рядом друг с другом, и, следовательно, близки по смыслу. Слова «Chops», «steak» и «pork» расположены еще ближе друг к другу.
Обратите внимание, что слова, которые находятся рядом друг с другом, не обязательно являются синонимами. Это могут быть слова, которые часто появляются близко друг к другу, как, например, «банан» и «яблоко».
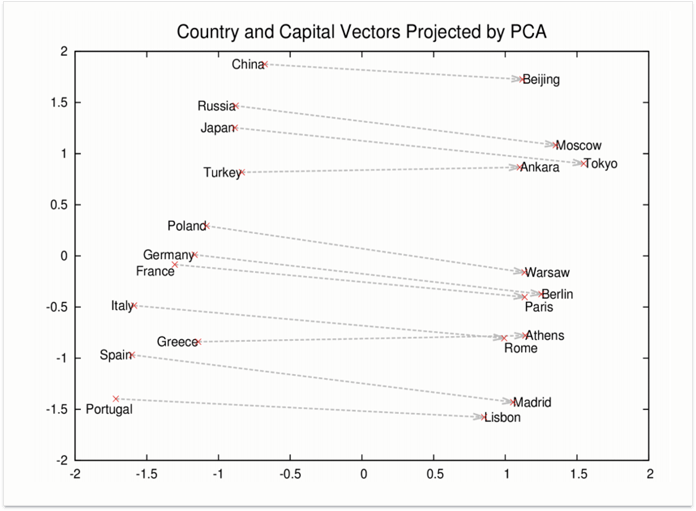
Теперь давайте разовьем это дальше. Мы выяснили, что мы можем вычитать векторы друг из друга для выявления их родства (чем меньше расстояние, тем больше связь). Но что, если сложить два вектора? А затем вычесть другой вектор из суммы? Видимо, это именно то, что Google делает в случае некоторых запросов.
Для указанных выше векторов, уравнение Rome - Italy + China будет равно Beijing. Это, по сути, векторное представление вопроса: «Что за объект имеет такое же отношение к Китаю, как Рим к Италии?», или просто: «Какой город является столицей Китая?»
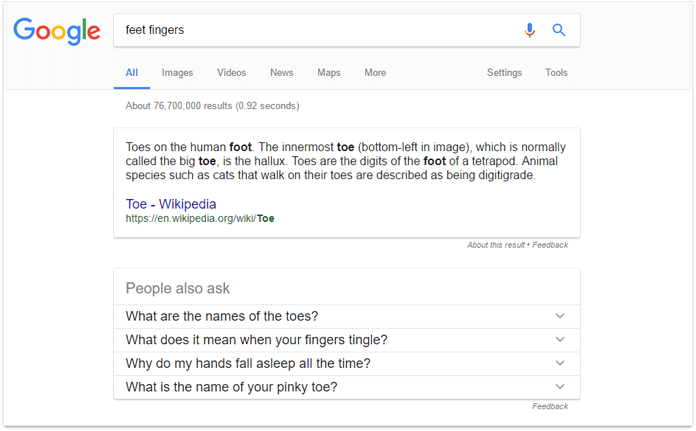
Вот пример того, как технология Word2Vec используется в обработке запроса. Предположим на минуту, что вы забыли слово «toe» (а вам позарез нужно это слово). Благодаря векторам поисковых запросов вы можете открыть Google и ввести запрос «feet fingers», и как бы странно это ни звучало, Google найдет то, что вы имели в виду. Он выяснит, что слово «fingers» относится к концепции «рука» и изменит запрос на что-то вроде: «Что имеет такое же отношение к слову «feet» (нога), как слово fingers («пальцы») к слову «hands» (руки)?» (или, в векторном представлении это будет выглядеть так: «foot + finger – hand») и будет искать недостающее звено в этой ассоциации. Благодаря этому, вы увидите именно то, что искали (вместо списка страниц, на которых упоминается как слово «feet», так и слово «fingers»).
Посмотрите, как они выделили жирным шрифтом «toe» в расширенном описании, при этом нет ни единого упоминания слова «finger»? Умно, да?
Объекты (Entities)
Объекты являются элементами Knowledge Graph от Google и представляют собой конкретные объекты, о которых Google знает некоторые факты, например, люди, места и вещи. Объектами могут быть компании, знаменитости или предприятия. Самое важное заключается в том, что Google обладает довольно большим объемом сведений о них, что позволяет пользователям мгновенно находить нужный объект по определенному факту.
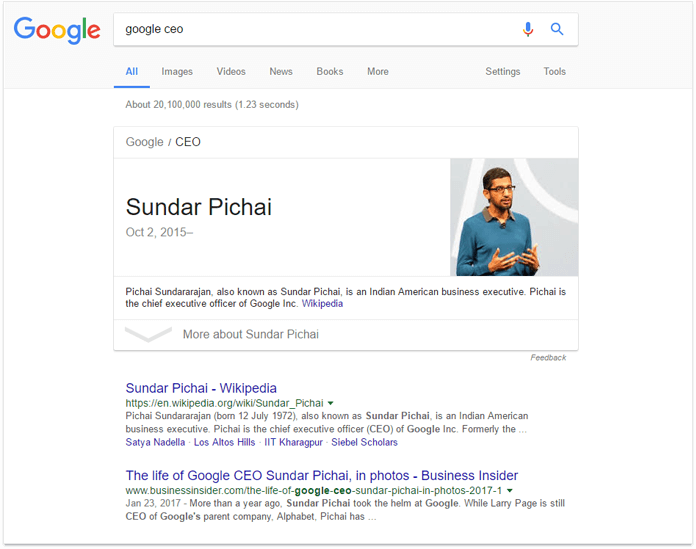
Таким образом, осуществление поиска по тому, что Google считает уникальным свойством определенного объекта, даст результаты поиска об этом объекте. Так, запрос «Самый большой город в мире» может превратиться в «Какой объект имеет уникальное свойство быть самым большим городом в мире?» и соответствовать объекту «город Токио». Аналогично, запрос «генеральный директор Google» будет соответствовать имени Sundar Pichai.
Интересно, что сигналы поведения пользователей могут повлиять на результаты поиска, связанные с конкретными объектами, как и в случае с любым другим типом результатов. Скажем, если Google находит два объекта с похожими весами, соответствующие запросу, он в большинстве случаев покажет результаты по ним обоим в выдаче. Если вы осуществляете поиск по запросу «Joe's NYC», при условии, что вы никогда не искали ничего по этому запросу ранее, вы получите результаты о ряде компаний с этим именем: Joe's bar, Joe's pub, Joe's coffee shop и Joe's pizza place.
Но как только вы кликните на определенный результат, скажем, на пиццерию, Google отнесет его к вашим предпочтениям в контексте этого поискового запроса. Поэтому при повторном выполнении аналогичного поиска этот более предпочтительный результат появится в верхней части результатов поиска, а страницы с информацией о других объектах будут полностью исключены из выдачи.
Заключительные слова
Вышеизложенное свидетельствует о том, что Google быстро становится умнее (даже человечнее) в определении контекста ключевых слов, перефразировании этих слов и предоставлении лучших результатов поиска в ответ на поисковый запрос. Мы можем считать это плохими или хорошими новостями, но мы мало что можем с этим сделать, как лишь приспособиться.
Я хотел бы, чтобы вы вынесли из этой статьи главный вывод: результаты поиска, которые пользователи видят в поисковой выдаче, это не только лишь сочетание самого запроса и факторов ранжирования. Попутно Google может изменять запрос так, чтобы лучше отвечать на него, и этот процесс модификации может быть очень разным для разных запросов и даже для одного и того же запроса, сделанного в разные моменты времени (представьте себе результаты поиска по запросу «Oscar», спустя несколько месяцев).
Так могут ли оптимизаторы все еще что-либо сделать, чтобы мы не запутались в этой семантической паутине? Конечно. Вот несколько советов:
1) Старайтесь попасть в Knowledge Graph. Несмотря на то, что не существует волшебной формулы, которая наверняка поможет сайту оказаться там, есть ряд шагов, которые позволят значительно увеличить шансы на попадание компании в панель знаний. Вот несколько шагов для локальной панели знаний и руководство для более универсальной панели Brand Knowledge Graph.
2) Боритесь за позиции. Меня всегда удивляет, как некоторые оптимизаторы начинают сомневаться в ценности высоких позиций сайта в поисковой выдаче из-за растущей персонализации поиска. Не забывайте, что когда кто-то осуществляет впервые поиск по таргетируемому вами ключевому слову, вы должны сделать все возможное, чтобы появиться среди топовых результатов.
Если вы этого добьетесь, и пользователь кликнет на ваш сайт, вы попадете в число его предпочтений, и его последующие схожие поисковые запросы будут, вероятно, выводить ваш сайт на первые позиции в выдаче. При этом он может быть даже единственным объектом в результатах поиска. В противном случае, если ваш конкурент окажется в ТОП-е, и пользователь кликнет на его ссылку в выдаче, вы, вероятно, потеряете такого клиента навсегда.
3) Внимательно мониторьте свою нишу. Теперь довольно ясно, что Google может использовать различные факторы ранжирования (и разные уточнения запроса) для разных ниш и даже отдельных запросов. Универсальный подход к SEO с его опорой на ссылки и структуру сайта все еще имеет место быть; но в контексте определенного запроса это может быть перевешано другими факторами, которые являются специфическими для этого запроса или ниши.
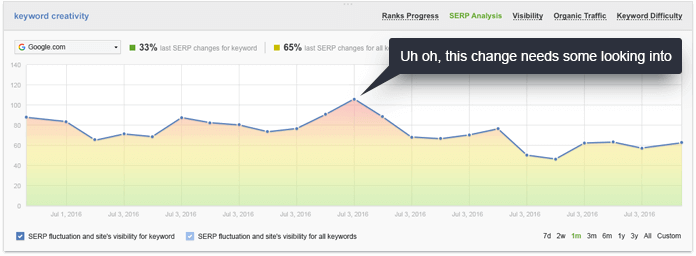
Вот где вступает в действие искусственный интеллект поисковой выдачи. В инструменте Rank Tracker от PowerSuite, например, мы называем это историей поисковой выдачи, архивом для первых 30 результатов поиска для каждой проверки позиций, которую вы запускаете.
Если посмотреть на график колебаний позиций сайта в выдаче, вы сможете мгновенно определить важные изменения в результатах поиска по каждому ключевому слову в каждой из проверок позиций. Красные пики на графике моментально дадут вам знать, что произошло важное изменение в выдаче, в котором необходимо разобраться.
Это может означать, что Google начал интерпретировать запрос по-другому или что он начал учитывать другие факторы ранжирования. В любом случае, необходимо осуществить проверку поисковой выдачи и провести анализ того, что изменилось. Таким образом, вы сможете быть первым, кто адаптировался к произошедшим изменениям.
|