|
|
DeepCrawl - краулинг дублированного контента
|
 |
25.08.2013, 06:18
|
|
#1
|
|
Регистрация: 02.07.2012
Сообщений: 648
|
| DeepCrawl - краулинг дублированного контента
|
Встречайте новый ресурс - DeepCrawl
На что он способен, как вы думаете после просмотра ролика? Да, вот и я в недоумении – презентация кислая без особого шика, блеска и красоты. Но не будем по одежке встречать… Давайте всё-таки узнаем, насколько DeepCrawl нам подходит.
DeepCrawl выполняет полный анализ архитектуры нашего сайта, чтобы помочь нам найти технические затыки, в том числе и дублированный контент, который негативно сказывается на отношение к сайту со стороны ПС.
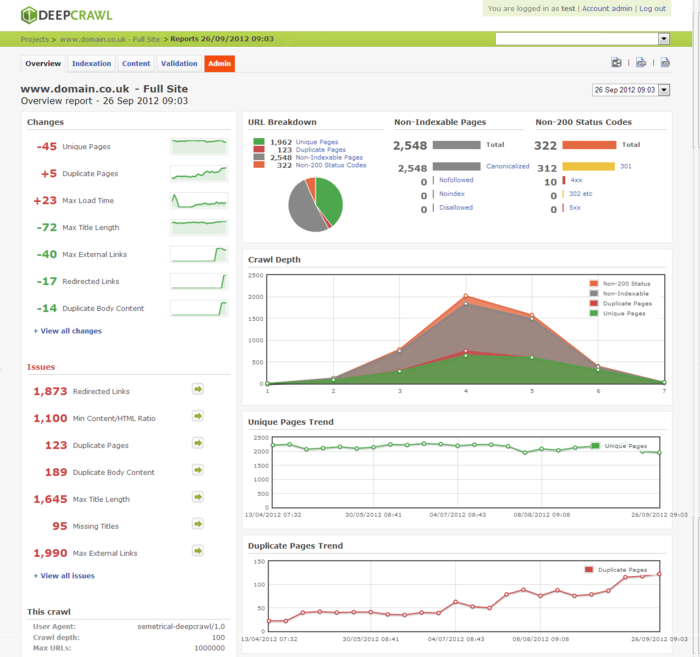
Давайте опустим все детали с регистрацией и перейдём сразу к техническим характеристикам этого сервиса. DeepCrawl способен регулярно сканировать весь сайт глубиной до 5000000 страниц и собирать различную информацию по всем аспектам, которые могут сказаться на имидже нашего сайта. Генерируемые отчёты на выходе содержат такие характеристики, как какое количество проиндексировано, сколько страниц не в индексе, информацию по тайтлам страниц, сколько страниц с дублированным контентом, сколько редиректов на сайте и т.д. Сам отчёт выглядит так
Как видите, тут и статистические данные, визуальные диаграммы и графики. Так что мы с легкостью можем, увидеть всю внутреннюю структуру сайта, которая сказывается на его позиции в Серпе. DeepCrawl дополнительно, оценивает каждый проанализированный сайт своей системой траста – Deeprank. Все отчёты можно, сохранить в самых популярных форматах у себя на ПК.
Визуализация архитектуры сайта
Если с цифровыми данными всё понятно, то стоит заострить внимание на генерируемых DeepCrawl визуальных графиках, которые строятся архитектуре нашего сайта, начиная с главной страницы и далее в глубину. Для построения используется количество уникальных страниц, дубликаты страниц, неиндексируемые URL-адреса и URL-адреса со статус кодом не - 200, это могут быть редиректы или неработающие ссылки.
Для большой наглядности стоит, остановиться на разных технических ситуациях, которые имеют место быть на сайте, для того, чтоб научится, читать графики DeepCrawl.
Совершенная архитектура
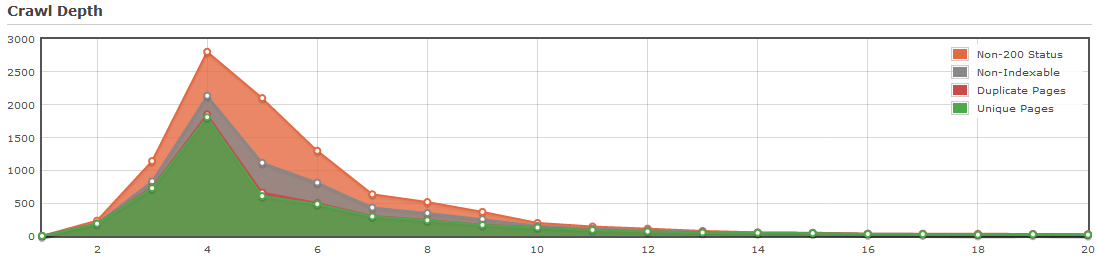
Сайт полностью состоит из индексируемых страниц, пик которых находится на 4 уровне, при этом весь сайт размещается до 8 уровня. Так, по мнению Дипкраулера, выглядит эффективная модель архитектуры сайта
Пагинация с длинным хвостом
Сайт с уникальным контентом, не очень зашумлён нетематическим контентом, но проблема с нумерацией страниц в архитектуре сайта и от этого страдают новые страницы, так как хвост тянется, аж до 35 уровня
Внутренняя перелинковка и длинный хвост
Из-за неправильно спланированной внутренней перелинковки страниц, URL-адресация становится слишком длинной для просмотра страниц поисковыми ботами при индексации, как всем известно, которые за первый прогон не ходят далее 2-3 вложенных страниц, поэтому вновь страдает уникализация страниц и как следствие, вновь слишком длинный хвост до 20 уровня
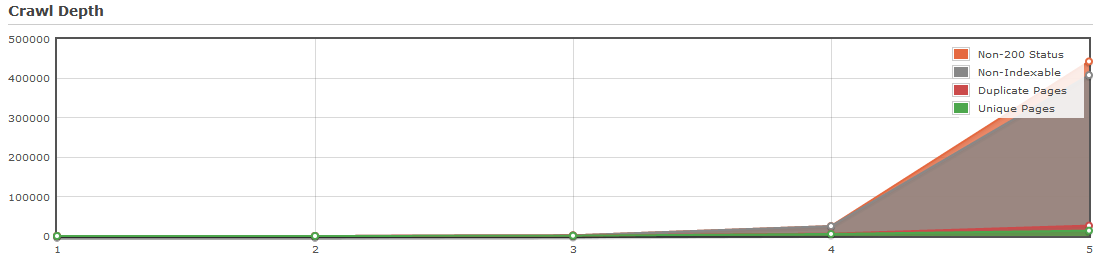
Тяжелая каноникализация
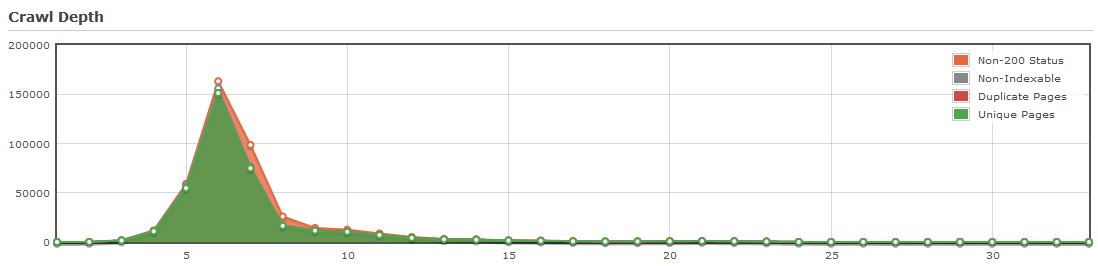
Перенасыщенность огромным количеством дополнительных URL-адресов на 4 уровне, которые отнимают много ресурсов во время индексации и занижают значение уникальных страниц сайта, что в итоге приводит к мало эффективной архитектуре краулинга поисковыми ботами
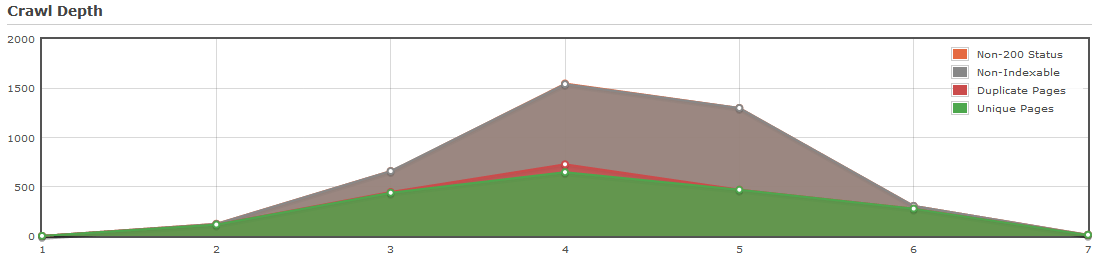
Малая каноникализация
Такая ситуация встречается часто на сайтах, так как не захламлённых сайтов контентом и хорошо структурированных по архитектуре с уникальными страницами, обнаруживающихся даже на 7 уровне очень много, этакие середнячки, не плохие, но и на отлично не тянут. В основном проблематика кроется в неэффективной каноникализации и составляет в среднем где-то 50%
Тяжёлое дублирование
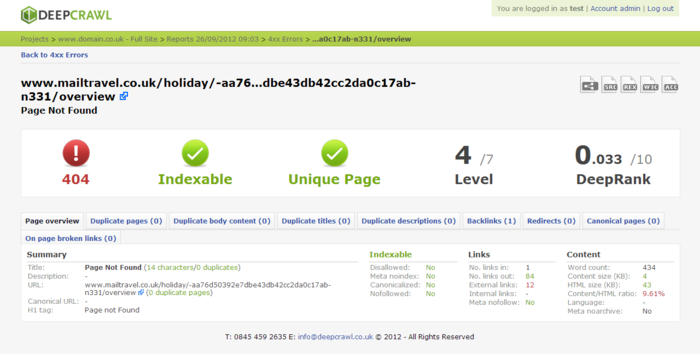
Тут вообще, даже объяснять не чего, сайт который не имеет ни какой оптимизации, в том числе и контента, так как большое количество дублей страниц, в том числе и УРЛ-адресов, полностью писсимизирует само понятие уникализации на этом сайте
Продвинутое сканирование для тех, кто в теме
Не секрет, что есть сайты, которые обычным методам сканирования не поддаются, так как там встроены циклические линки или ещё какие-нибудь технологии, скрывающие техники линковки сайта. Тут то и сгодится умное сканирование, когда во время парсинга используются специальные фильтры на базе регулярных выражений. Так мы можем заблокировать при парсинге сотни тысяч спам ссылок и прочего балласта, который нам просто не интересен. Благодаря такому подходу краулинг сайта становится гораздо легче и эффективнее, не говоря уже об экономии временных ресурсов.
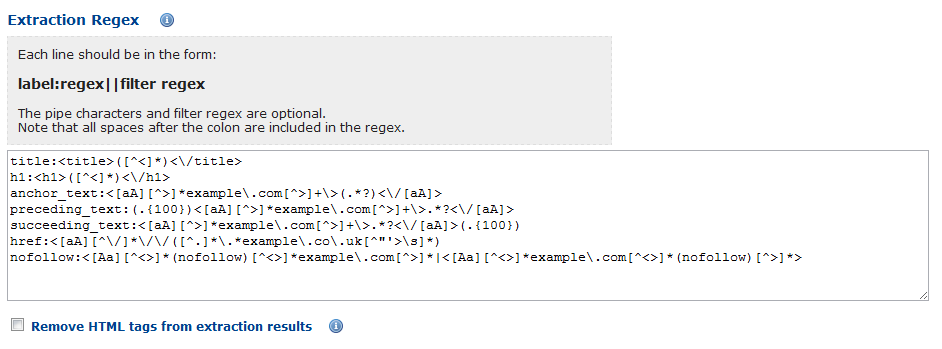
Обычно для фильтров составляют файл REGEX, который и содержит регулярные выражения для фильтрации при умном парсинге. Вот скриншот одного из регекс-файлов
Что ещё прельщает в таком подходе, так это, то что мы можем ввести регулярные выражения, которые будут, отрабатывать к каждой отдельно взятой странице при парсинге. Нечто похожее реализовано в СкрименФроге, где мы можем загрузить уже готовый текстовый файл со списком URL-адресов и провести сканирование.
Что обычно интересует при парсинге, так это служебная информация о техническом состоянии любой веб-страницы. Поэтому DeepCrawl при парсинге уже по умолчанию настроен на извлечение обратных ссылок, служебной информации и проверку тегов.
Для использования продвинутого режима краулинга, вам надо в DeepCrawl при создании нового проекта во вкладке " Дополнительные параметры " прописать свои предпочитаемые правила для персонального парсинга. После завершения парсинга нам на выбор будет представлено два варианта отчёта, первый будет, содержать все URL-адреса, которые соответствуют хотя бы одному из наших пользовательских правил, а второй отчет наоборот будет, содержать все URL-адреса, которые не соответствует ни одному из наших расширенных настроек для парсинга.
Синтаксис регулярных выражений для извлечения данных выглядит так ...
{extraction label}:{extraction regex}||{extraction exception}
| | {} – в этой области мы и можем указать исключения или ещё какие-нибудь дополнительные настройки для фильтрации при парсинге. Можно задействовать ещё такой синтаксис {0 .. N} , который позволит извлекать информацию для 3 аккаунтов Google Analytics
account:{0..3}(UA-[0-9]+-[0-9]+)
Расширенный вариант регекса для отслеживания кодов Google Analytics выглядит так:
Google Analytics:(google-analytics\.com\/ga\.js)|(\/ga\.js)|(www\.google-analytics\.com\/urchin\.js)|(\/urchin\.js)
Webtrends:(webtrends\.js)|(\/js\/WTTag)|([w][e][b][t][r][e][n][d][s])
Omniture:(SiteCatalyst code)|(s\.prop)|(omniture)
Nielsen:(SiteCensus)|(nielsen\.js)
YahooWebAnalytics:(ywa\.js)
Statcounter:(StatCounter Code)|(statcounter\.com\/counter\.php)|(statcounter\.com\/counter\/counter\.js)
Chartbeat:(chartbeatdev\.js)|(chartbeat\.js)
Woopra:(woopra\.v.\.js)|(woopra\.js)
Sitemeter:(sitemeter\.com\/js\/counter\.js)
SageMetrics:(sageanalyst\.net)
Hitbox:(hbx\.js)|(hbx\.acct)
QuantCast:(quant\.js)|(quantcast\.js)
comScore:(\/beacon\.js)|(beacon\.dll)|(comScore Tag)
Sophus:(js\/sophus\/logging\.js)|(sophus3)
Intellitracker:(intelli-direct\.com\/)
Foviance:(foviance\.js)
Piwik:(piwik\.js)
Histats:(histats\.com)
Gemius:(gemius\.js)
Maxymiser:(mmcore\.js)
Tynt:(tcr\.tynt\.com)
DoubleClick Floodlight:(fls\.doubleclick\.net)
DoubleClick DFA:(ad\.doubleclick\.net)
Marin:(tracker\.marinsm\.com)
Revenue Science:(/js\.revsci\.net)
AdSense:(googlesyndication\.com\/pagead\/show_ads\.js)
ClickDensity:(j\.clickdensity\.com\/cr\.js)
А для получения со страниц служебной информации о Google Analytics Tracking Tag, можно задействовать следующее выражение:
GAAccounts:{0..3}(UA-[0-9]+-[0-9]+)
GAPagename:_trackPageview’,\s’(.*?)’]|trackPageview\(“(.*?)”\);|urchinTracker\(‘(.*?)’\);
GAVersion:(pageTracker\._trackPageview\()|(gaq\.push\(\['_trackPageview')|(urchinTracker)
GAcustomvar1:setCustomVar',\s*1,\s*(.*?)\]\)
GAcustomvar2:setCustomVar’,\s*2,\s*(.*?)\]\)
GAcustomvar3:setCustomVar’,\s*3,\s*(.*?)\]\)
GAcustomvar4:setCustomVar’,\s*4,\s*(.*?)\]\)
GAcustomvar5:setCustomVar’,\s*5,\s*(.*?)\]\)
GAEvents:{0..5}_gaq\.push\(\['_trackEvent',(.*?)\]\)
Если вдруг случится, что вы захотите пробить содержимое на наличие тегов Omniture на страницах сайта, то это с легкостью можно сделать, использовав следующую регулярку:
OmniPagename:s\.pageName\s*=\s*['"](.+?)['"];
OmniChannel:s\.channel\s*=\s*['"](.+?)['"];
OmniChannel:s\.server\s*=\s*['"](.*?)['"]
OmniSPROP25:prop25\s*=\s*['"](.*?)['"]
OmniSPROP8:prop8\s*=\s*['"](.*?)['"]
OmniSPROP9:prop9\s*=\s*['"](.*?)['"]
OmniSPROP10:prop10\s*=\s*['"](.*?)['"]
OmniSPROP27:prop27\s*=\s*['"](.*?)['"]
Извлечение содержимого тега Meta Keywords делается по следующей директиве:
Keywords:name\s*=\s*['"]?keywords[^>]+content\s*=\s*['"]?([^'"]*)['"]?|content=['"]?([^"']*)['"]?[^>]+name=['"]?keywords['"]?
Для эстетов можно, забацать информации о наличии кнопок Like, вот так
LikeButtonJavaScript:(<fb:like)
LikeButtonIframe:(facebook\.com\/plugins\/like\.php)
LikeBox:(facebook\.com\/plugins\/likebox\.php)
Или же собрать отчёт по тегам Open Graph
XMLNSOG:xmlns:og\s*=\s*['"]?([^'"]*)['"]?
XMLNSFB:xmlns:fb\s*=\s*['"]?([^'"]*)['"]?
OGTitle:<meta property\s*=\s*['"]?og:title['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGType:<meta property\s*=\s*['"]?og:type['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGURL:<meta property\s*=\s*['"]?og:url['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGImage:<meta property\s*=\s*['"]?og:image['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGSitename:<meta property\s*=\s*['"]?og:site_name['"]? content\s*=\s*['"]?([^'"]*)['"]?
FBAdmins:<meta property\s*=\s*['"]?fb:admins['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGDescription:<meta property\s*=\s*['"]?og:description['"]? content\s*=\s*['"]?([^'"]*)['"]?
FBPageID:<meta property\s*=\s*['"]?fb\:page_id['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGLatitude:<meta property\s*=\s*['"]?og:latitude['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGLongitude:<meta property\s*=\s*['"]?og:longitude['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGStreetaddress:<meta property\s*=\s*['"]?og:street-address['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGLocality:<meta property\s*=\s*['"]?og:locality['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGRegion:<meta property\s*=\s*['"]?og:region['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGPostalcode:<meta property\s*=\s*['"]?og:postal-code['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGCountryname:<meta property\s*=\s*['"]?og:country-name['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGEmail:<meta property\s*=\s*['"]?og:email['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGPhonenumber:<meta property\s*=\s*['"]?og:phone_number['"]? content\s*=\s*['"]?([^'"]*)['"]?
OGFaxnumber:<meta property\s*=\s*['"]?og:fax_number['"]? content\s*=\s*['"]?([^'"]*)['"]?
Если ещё не устали, то вот регулярное выражение для извлечения о Twittercard Markup
TwittercardCard:<meta name\s*=\s*['"]?twitter:card['"]? content\s*=\s*['"]?([^'"]*)['"]?
TwittercardSite:<meta name\s*=\s*['"]?twitter:site['"]? content\s*=\s*['"]?([^'"]*)['"]?
TwittercardCreator:<meta name\s*=\s*['"]?twitter:creator['"]? content\s*=\s*['"]?([^'"]*)['"]?
TwittercardURL:<meta name\s*=\s*['"]?twitter:url['"]? content\s*=\s*['"]?([^'"]*)['"]?
TwittercardTitle:<meta name\s*=\s*['"]?twitter:title['"]? content\s*=\s*['"]?([^'"]*)['"]?
TwittercardDescription:<meta name\s*=\s*['"]?twitter:description['"]? content\s*=\s*['"]?([^'"]*)['"]?
TwittercardImage:<meta name\s*=\s*['"]?twitter:image['"]? content\s*=\s*['"]?([^'"]*)['"]?
Есть конечно же регулярка и для Schema.org
schema-itemtype:itemtype=\”http:\/\/schema\.org\/([^\"]*)
schema-itemprop:itemprop=\”([^\"]*)
schema-breadcrumb:(itemprop=\”breadcrumb\”)
schema-review:(itemtype=\”http:\/\/schema\.org\/Review”)
Ещё один вариант для получения IP-адреса
IPAddress:(\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b)
И наиболее обиходный вариант регулярки для отчёта по атрибутам URL-адресов с относительной адресацией "Далее" или "Назад"
rel-prev2:<link.rel=['"]?prev['"]?.href=['"]?([^"'\s>]*)
rel-next2:<link.rel=['"]?next['"]?.href=['"]?([^"'\s>]*)
На этом заканчиваю. Надеюсь, вы с легкостью освоите DeepCrawl и регулярно будете им пользоваться.
Успехов.
|
|
|
 |

|
Здесь присутствуют: 1 (пользователей: 0, гостей: 1)
|
|
|
|