|
|
Как провести анализ цен товаров конкурентов
|
 |
07.02.2016, 22:06
|
|
#1
|
|
Регистрация: 30.07.2014
Сообщений: 474
|
| Как провести анализ цен товаров конкурентов
|
Всегда хотели бы узнать, какие цены конкуренты устанавливают для своих товаров? Возможно, вы хотели бы отслеживать изменения в их ценах, чтобы можно быстро отреагировать или просто отслеживать тенденции. Я хочу показать вам хак, который я использовал в прошлом и продолжаю применять (особенно для e-commerce проектов) для мониторинга цен конкурентов, и как этот процесс можно автоматизировать.
Вам не только не понадобится дорогостоящее и не всегда точное ПО для анализа деятельности конкурентов, но вы получите полный контроль над тем, какие данные вы хотите получить в любой момент, при этом нет абсолютно никаких ограничений по частоте осуществления этих операций. Звучит неплохо, верно?
Что вам потребуется
Вам понадобится несколько вещей – ничего значительного или дорого, и все необходимые инструкции вы получите в этом посте:
1. Подписка на URL Profiler ($15,95 в месяц).
2. Microsoft Excel.
3. Базовые знания кода HTML и CSS (я покажу то, что вам нужно знать).
Введение
Кратко процесс сбора данных о ценах конкурентов выглядит так:
• Сбор URL-адресов страниц товаров конкурентов
• Выявление элементов на странице, информацию с которых необходимо извлечь
• Написание селекторов CSS/xpath-запросов
• Извлечение данных через URL Profiler
• Организация данных в таблице
Шаг 1: Сбор URL-адресов страниц товаров конкурентов
Первым шагом в этом процессе выступает сбор URL-адресов страниц товаров конкурентов, на которых вы хотите мониторить цены. Существует три основных способа получить URL-адреса:
1. Подтянуть их из карты сайта конкурентов.
2. Обойти сайт с помощью одного из инструментов, например, Screaming Frog SEO Spider или Deep Crawl.
3. Взять их со страниц листинга на их сайте (я не буду вдаваться в подробности, потому что для этого необходимо написать отдельный пост).
Первый способ является самым простым. Единственная причина, по которой стоит воспользоваться способами 2 и 3 – если у вашего конкурента нет файла sitemap. Чтобы найти данный файл, зайдите в Google и наберите следующий запрос, заменив COMPETITOR-DOMAIN именем домена сайта конкурента (например, amazon.com):
site:COMPETITOR-DOMAIN inurl:sitemap OR filetype:xml
В некоторых случаях вы получите несколько результатов с разными файлами sitemap. Это происходит потому, что множество сайтов, особенно крупные e-commerce сайты обладают несколькими файлами sitemap. Вам просто необходимо будет вручную найти правильный.
Как только вы найдете файл sitemap, скопируйте URL-адреса и затем воспользуйтесь этим удивительным инструментом URL extractor tool от Rob Hammond, который предоставит список всех URL-адресов из файла sitemap без каких-либо других данных. Затем вы можете скопировать и вставить эту информацию в новую таблицу Excel.
Если вы не можете найти файл sitemap, вам придется обойти сайт, чтобы подтянуть все URL-адреса. Я не хочу вдаваться в подробности этого процесса, потому что здесь все очень просто, если загрузить специальное программное обеспечение. Я бы посоветовал использовать для этого сервис Screaming Frog SEO Spider, обладающий бесплатной версией. Все, что нужно будет сделать, это добавить домен конкурента, и сервис подтянет все URL-адреса с сайта.
Получив все URL-адреса, далее необходимо отфильтровать страницы товаров. Иногда это легко сделать, так как в их адресе есть специальная добавка, например /product/. В этом случае, просто используйте фильтр в Excel для отбора адресов, содержащих /product/.
В том случае, если нет подобного способа отличить URL-адрес страницы товара, не волнуйтесь, так как вы сможете использовать в нашем процессе все URL-адреса, и те, которые не принадлежат страницам товаров, будут возвращать пустой результат.
Шаг 2: Выявление элементов на странице, информацию с которых необходимо извлечь
Следующий шаг в данном процессе - определить элементы на страницах, информацию с которых вы хотите извлечь (т. е. цена). Здесь вам понадобятся базовые знания HTML и CSS.
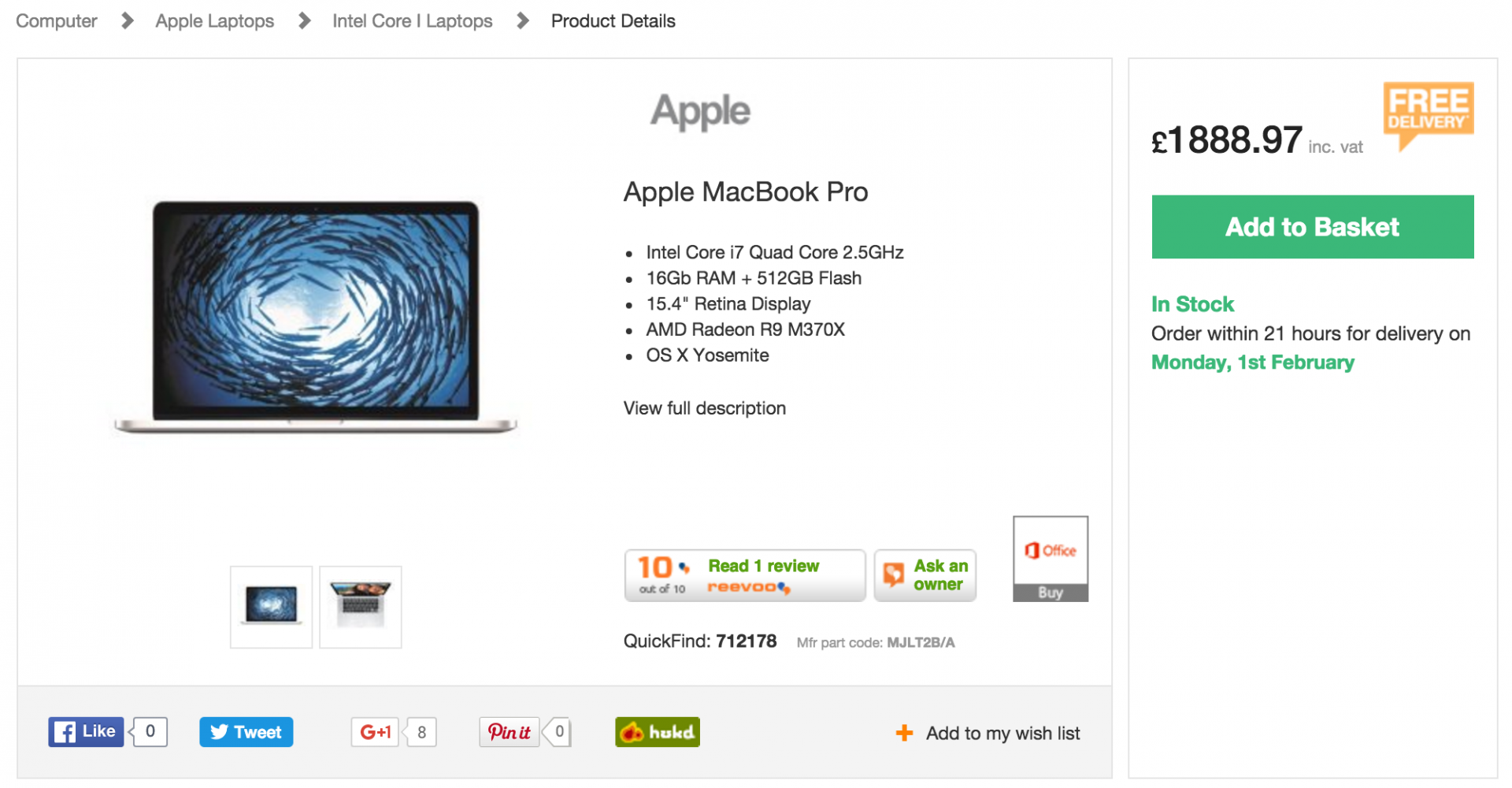
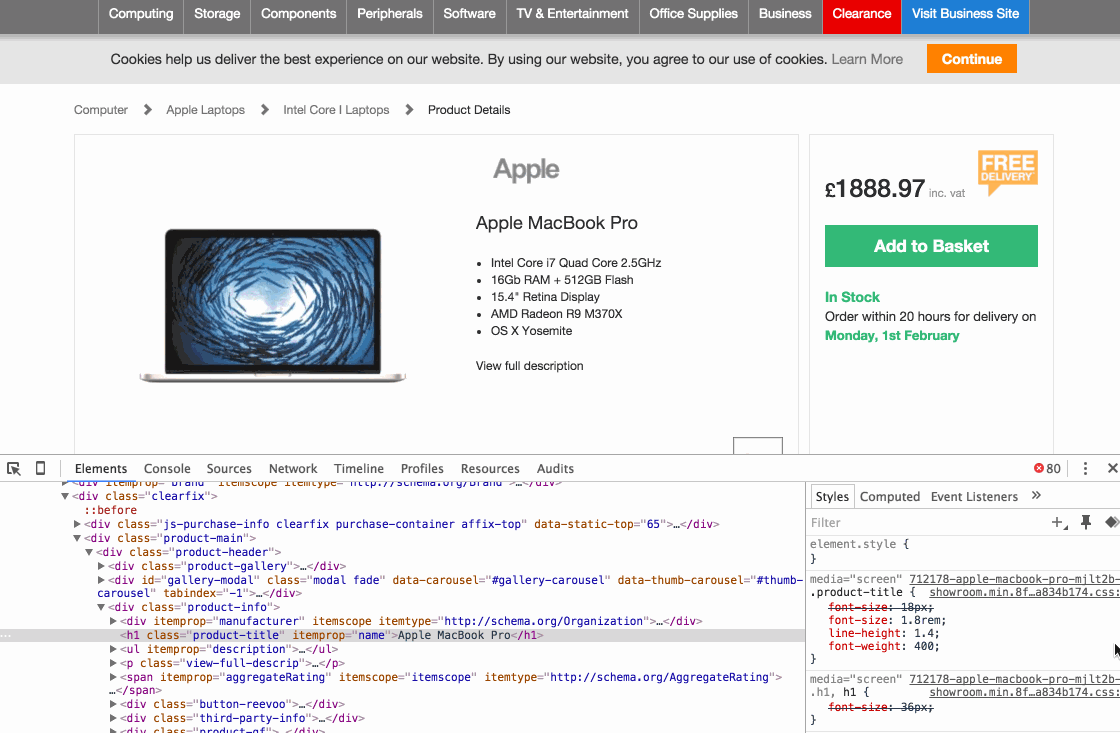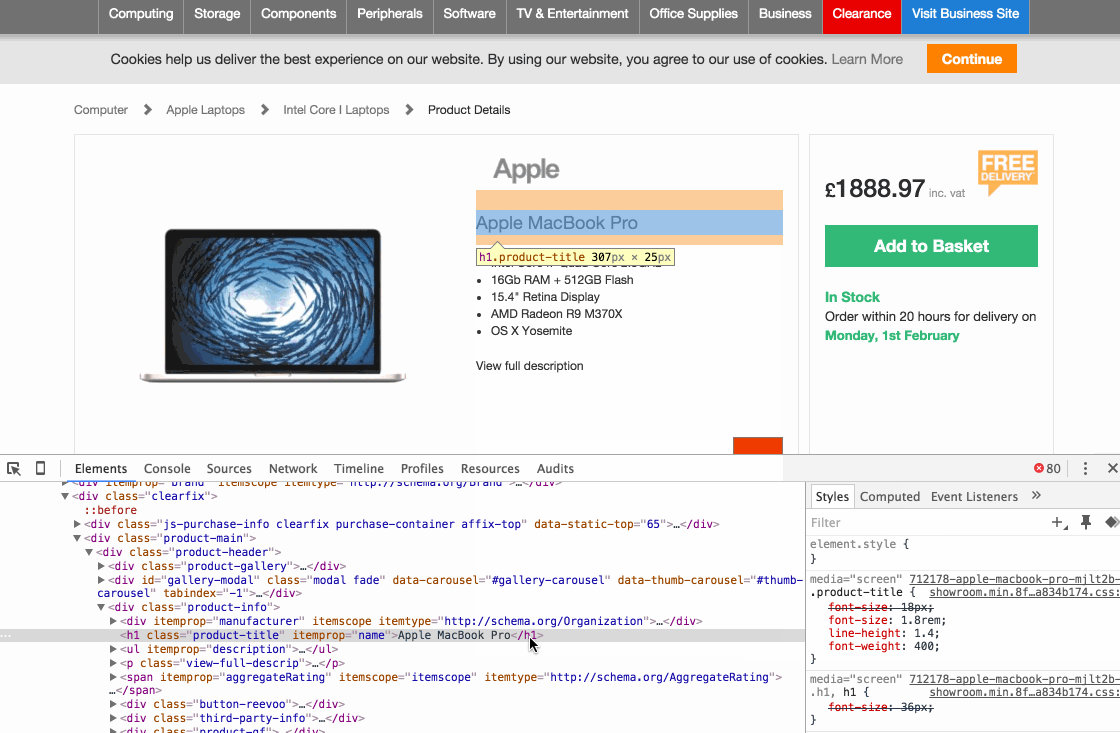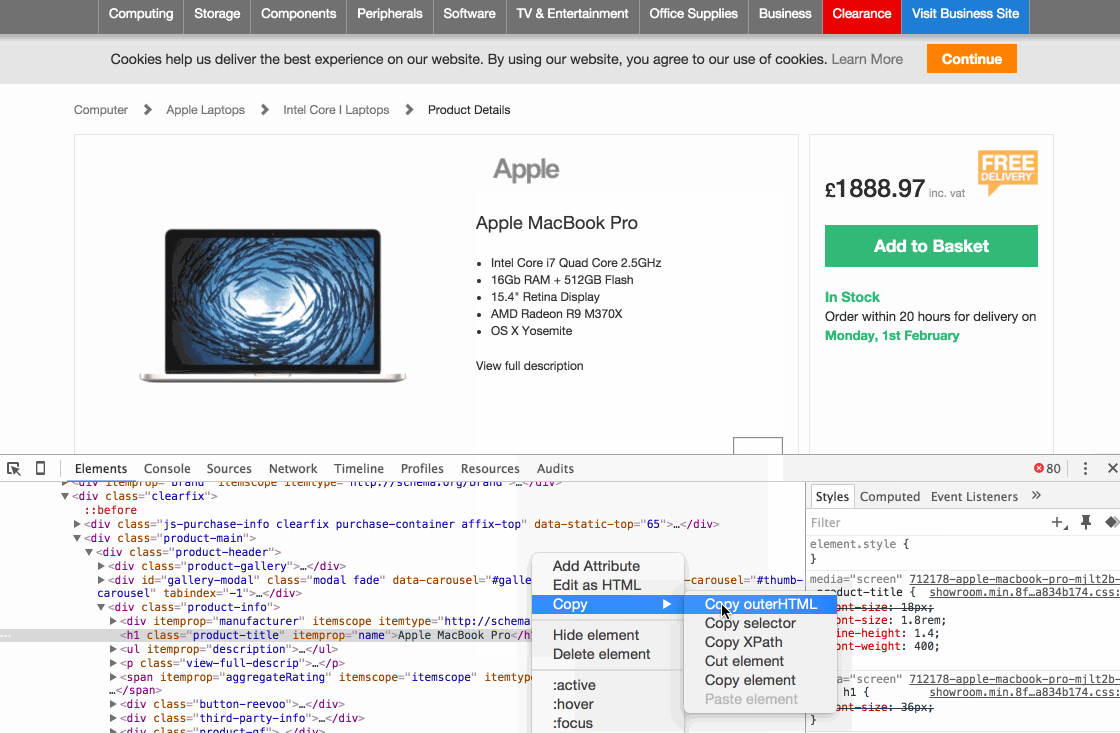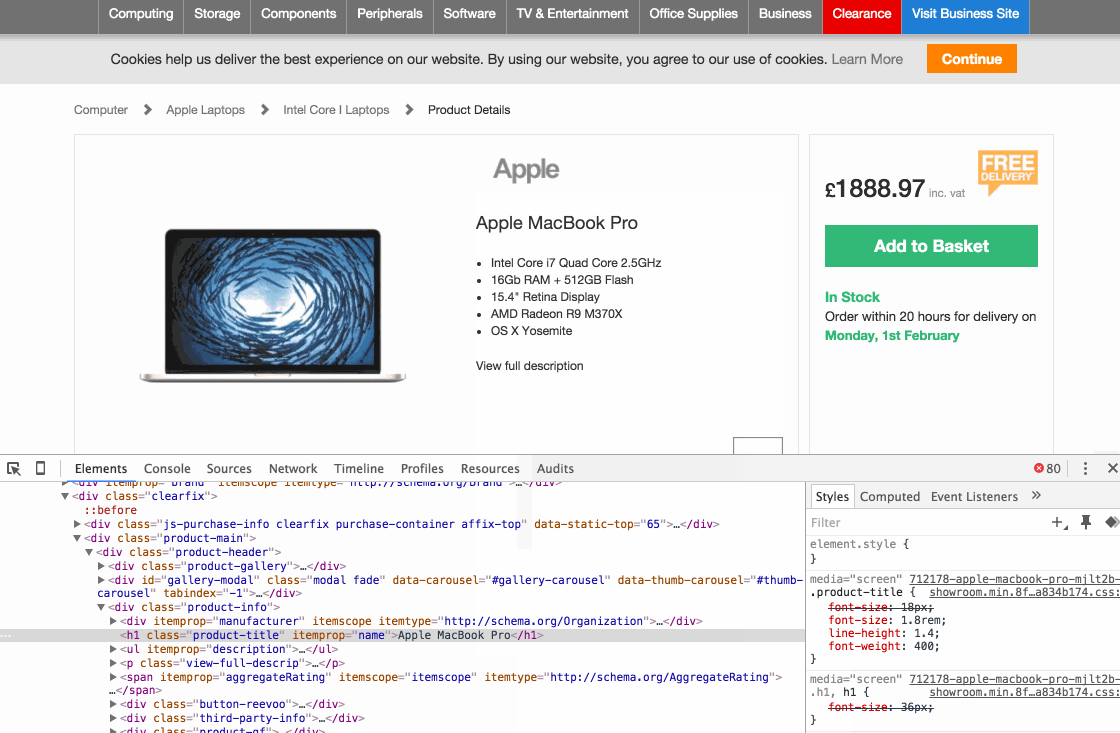
Прежде всего, зайдите на одну из страниц товара конкурента. Здесь для примера я буду использовать Ebuyer.com в качестве страницы продукта конкурента:
Вот URL-адрес страницы товара выше, чтобы вы могли следить за тем, что мы будем делать. Для конкурентного анализа цен, я, возможно, хочу, подтянуть следующие данные для каждого продукта:
1. Наименование товара.
2. Цена.
3. Категория товара.
4. Есть ли товар в наличии.
5. Описание продукта.
Стоит отметить, что вся эта информация должна визуально присутствовать на страницах товара для того, чтобы вы могли ее извлечь. Давайте начнем с названия продукта, чтобы показать, как определить HTML-элемент, содержащий эту информацию:
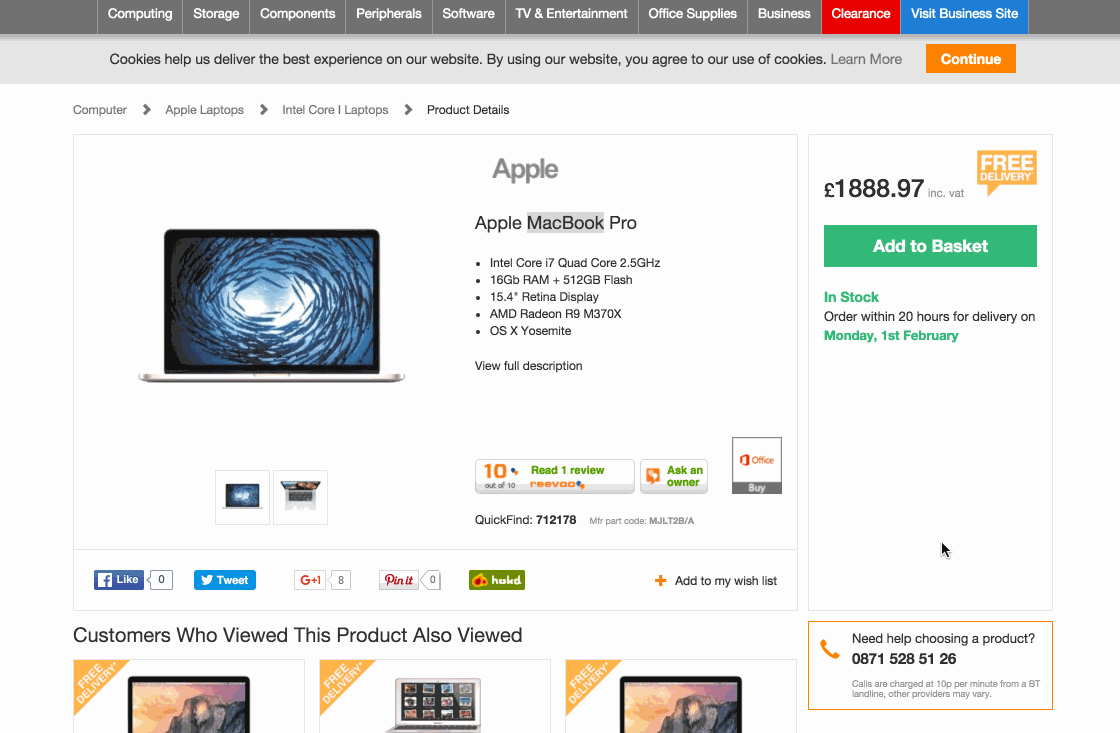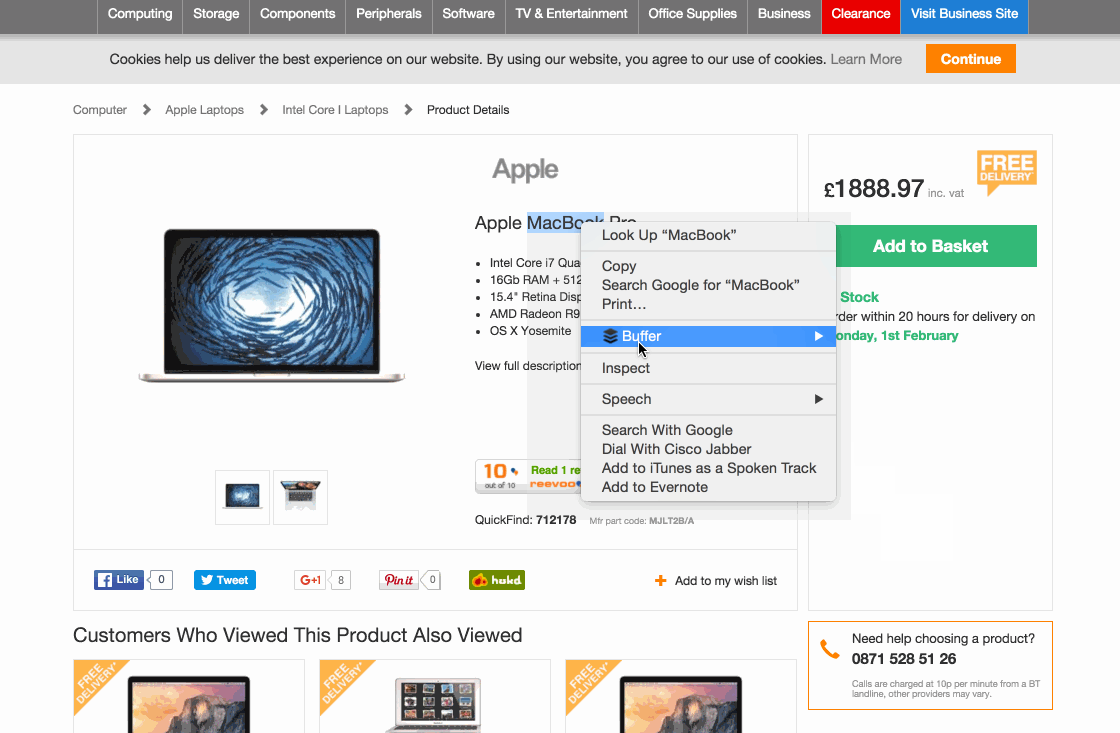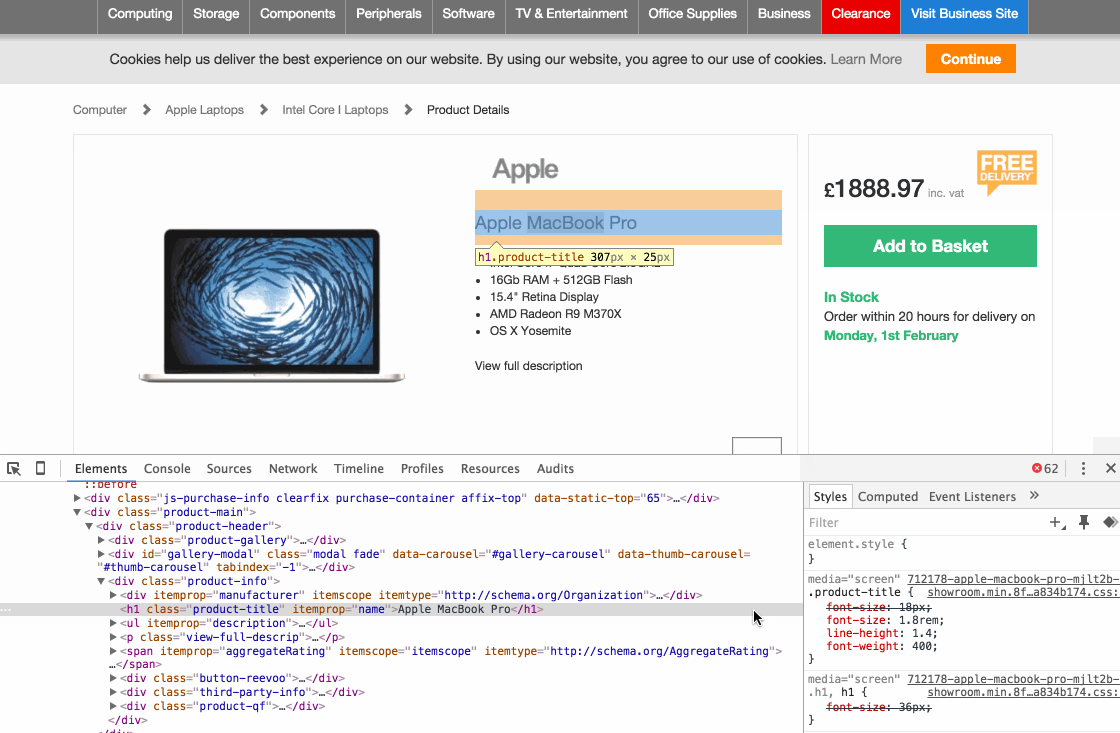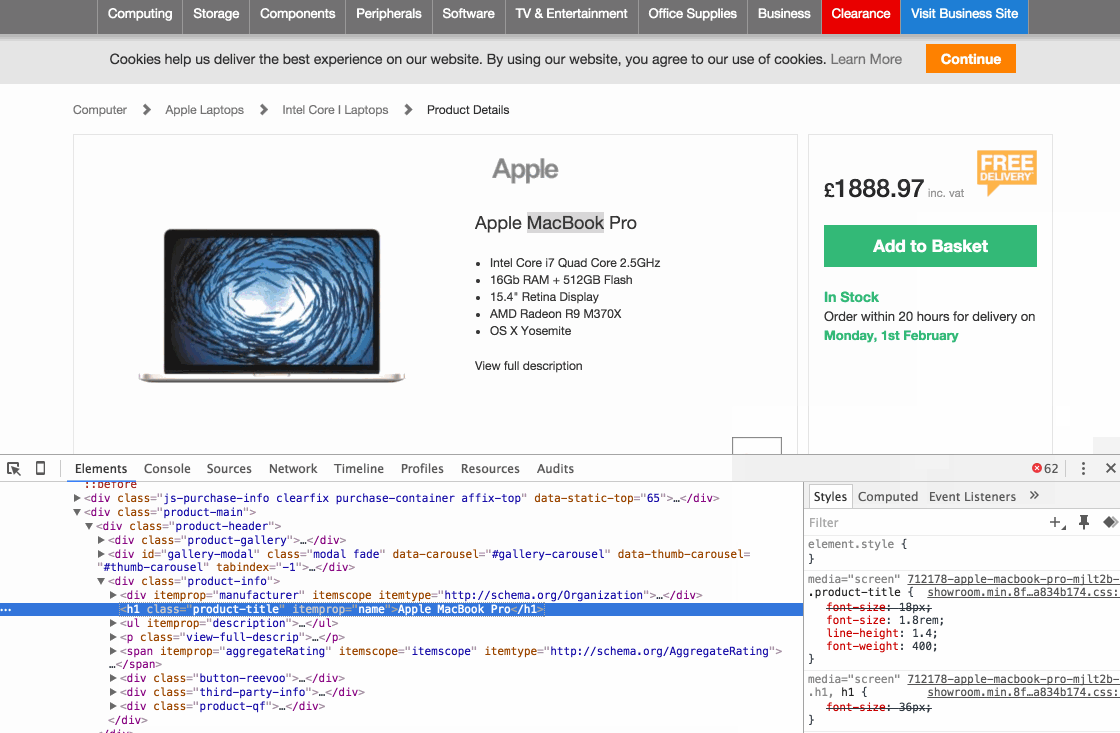
1. Откройте страницу товара в Google Chrome.
2. Определите, где на странице товара отображается название.
3. Щелкните правой кнопкой мыши на него.
4. Выберите «Просмотреть код» из меню.
5. Посмотрите на строчку кода, выделенную в окне, появившемся в нижней части браузера.
6. HTML-элемент, который содержит наименование товара - это то, что мы ищем.
Вот наглядное описание этого процесса:
В примере выше в качестве элемента HTML выступал заголовок H1 с классом «product-title». Теперь, когда у вас есть HTML-элемент, пришло время построить xpath-запрос или CSS селектор для извлечения данных.
Шаг 3: Составить xpath-запрос или CSS селектор
Этот шаг связан с общением с программным обеспечением для того, чтобы сообщить ему, где найти информацию, которую вы хотите извлечь в пределах веб-страницы. Для этого мы используем либо CSS selector либо XPath. Я не хочу вникать во все подробности того, что из себя представляют эти инструменты, потому что вам действительно не нужно этого знать. Однако если вы хотите узнать больше, зайдите на W3Schools.
На этом шаге мы возьмем в качестве основы Шаг 2. Давайте вернемся к нахождению элемента с наименованием товара с помощью 6 шагов, которые я изложил выше. Все, что вам нужно сделать, это щелкнуть правой кнопкой мыши по строке кода в Developer Tools, а затем выбрать Copy > Copy selector. Вот наглядное пошаговое руководство:
Так вы скопируете код CSS селектора в буфер обмена. Просто откройте пустой текстовый редактор и вставьте код, чтобы начать отслеживать его. Не забудьте написать рядом, к какому типу данных он относится (т. е. наименование товара). В приведенном выше примере, CSS селектор:
#main-content > div > div:nth-child(1) > div.clearfix > div.product-main > div.product-header > div.product-info > h1
Это то, что необходимо для следующего шага, чтобы идентифицировать элементы, которые мы хотим извлечь. Хочу вас предупредить, что такой способ получения CSS селектора может быть немного неточным (по причинам, объяснять которые, у меня нет времени). Если вы хотите быть полностью уверены, что это будет работать, вы можете написать свой xpath-запрос.
Чтобы сделать это, нам нужно знать несколько вещей об HTML-элементе, содержащем необходимые данные. Первое, нам нужно знать, какого рода HTML-элемент перед нами (например, h1, div, p, a, span и др.). Это первое слово после символа «<». В моем примере вся строка кода выглядит так:
<h1 class="product-title" itemprop="name">Apple MacBook Pro</h1>
В этом случае HTML-элемент - Н1. Вторая часть информации, которая нам нужна, это уникальный атрибут. В этой строке кода есть два атрибута, «class» и «itemprop».
Уникальный идентификатор для атрибута class – «product-title», а для атрибута itemprop – «name». Это все, что нам нужно идентифицировать для данного конкретного фрагмента данных. Теперь нам нужно превратить это в xpath- запрос.
Вот структура xpath- запроса, где жирным указано, куда нужно добавить HTML-элемент, атрибут и уникальный идентификатор:
//element[@attribute="unique identifier"]
Итак, используя этот синтаксис, xpath-запрос для моего примера выглядит так:
//h1[@class="product-title"]
Или если мы используем itemprop как атрибут для идентификации (вместо class):
//h1[@itemprop="name"]
Вы сами решаете, какой атрибут использовать. Вам необходимо сделать это для каждого из элементов страницы, которые вы хотите извлечь. Еще один пример - код для цены товара на Ebuyer.com:
<span itemprop="price">1888.97</span>
В данном случае, HTML элемент – «span», атрибут - «itemprop» и уникальный идентификатор – «price». Xpath-запрос будет выглядеть следующим образом:
//span[@itemprop="price"]
Шаг 4: Извлечение данных через URL Profiler
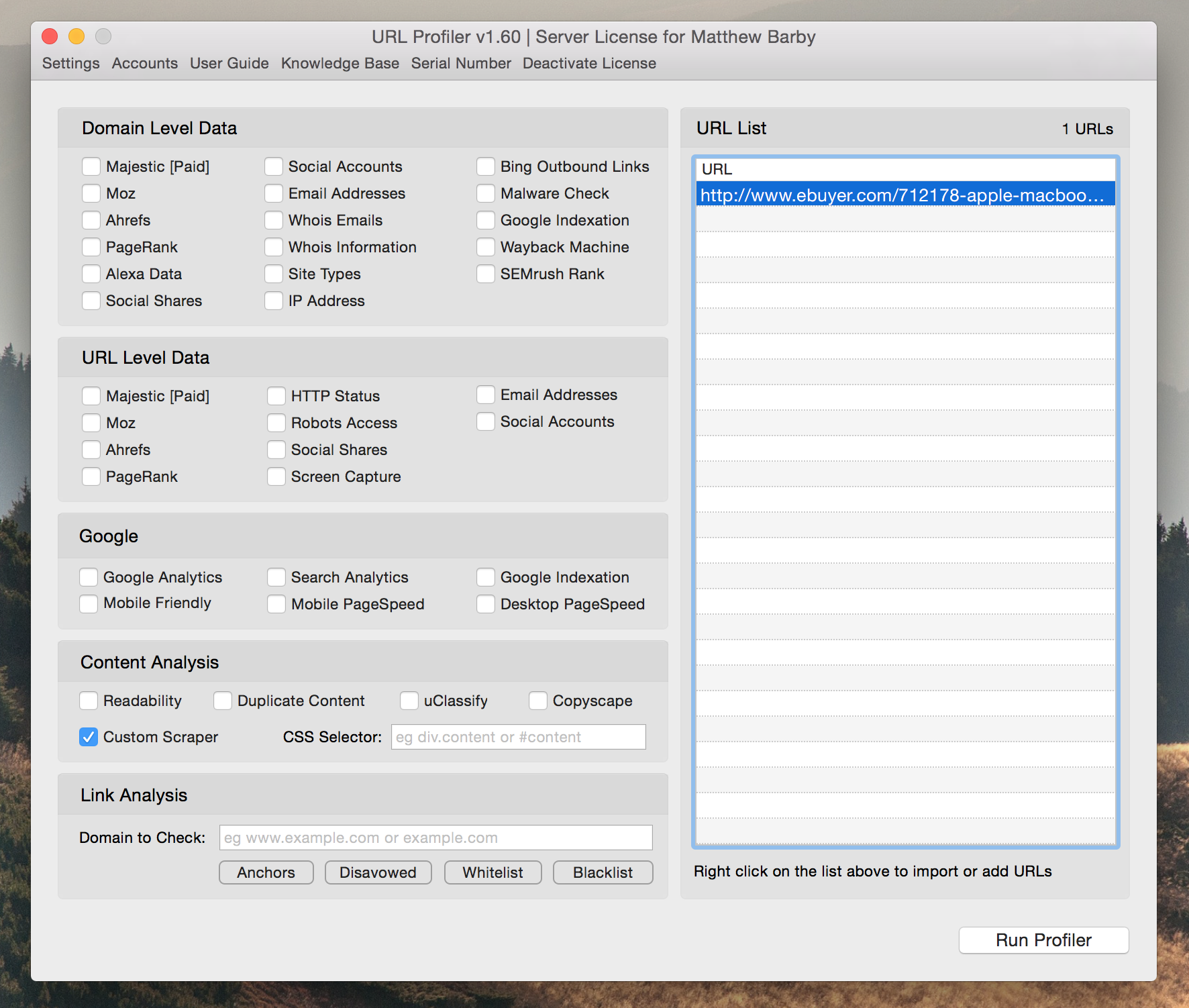
Здесь начинается самое приятное. Откройте URL Profiler и снимите все галочки, которые могли быть предварительно выбраны. В качестве теста добавьте только один URL-адрес страницы товара конкурента в поле справа. Просто скопируйте и вставьте URL-адрес в окно.
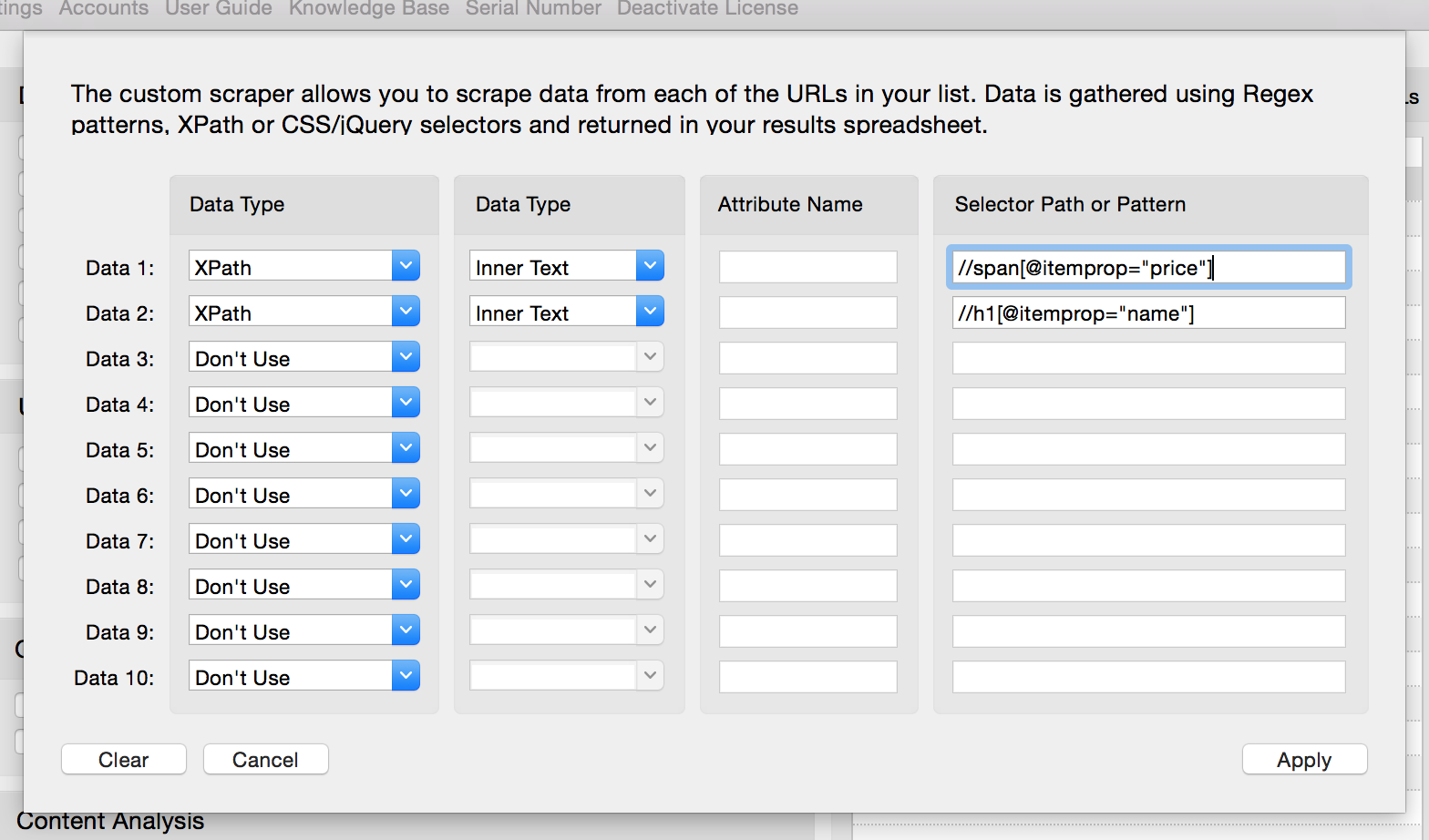
Теперь выберите опцию «Custom Scraper». Как только вы нажмете эту кнопку, откроется новое окно. Здесь добавьте CSS-селекторы или xpath- запросы. Вы можете добавить до 10 элементов данных одновременно; все, что нужно – убедиться, что вы выбрали правильный тип данных для каждого из них. Если вы пошли по пути написания собственного xpath-запроса, то нужно будет выбрать в поле Data type «XPath», как показано ниже:
Если Вы использовали CSS-селекторы, выберите тип данных «CSS». После того, как вы добавили соответствующие CSS селекторы или xpath-запросы для каждого фрагмента данных, которые вы хотите извлечь, нажмите кнопку «Apply». Теперь кликните на «Run Profiler» и программа начнет работать.
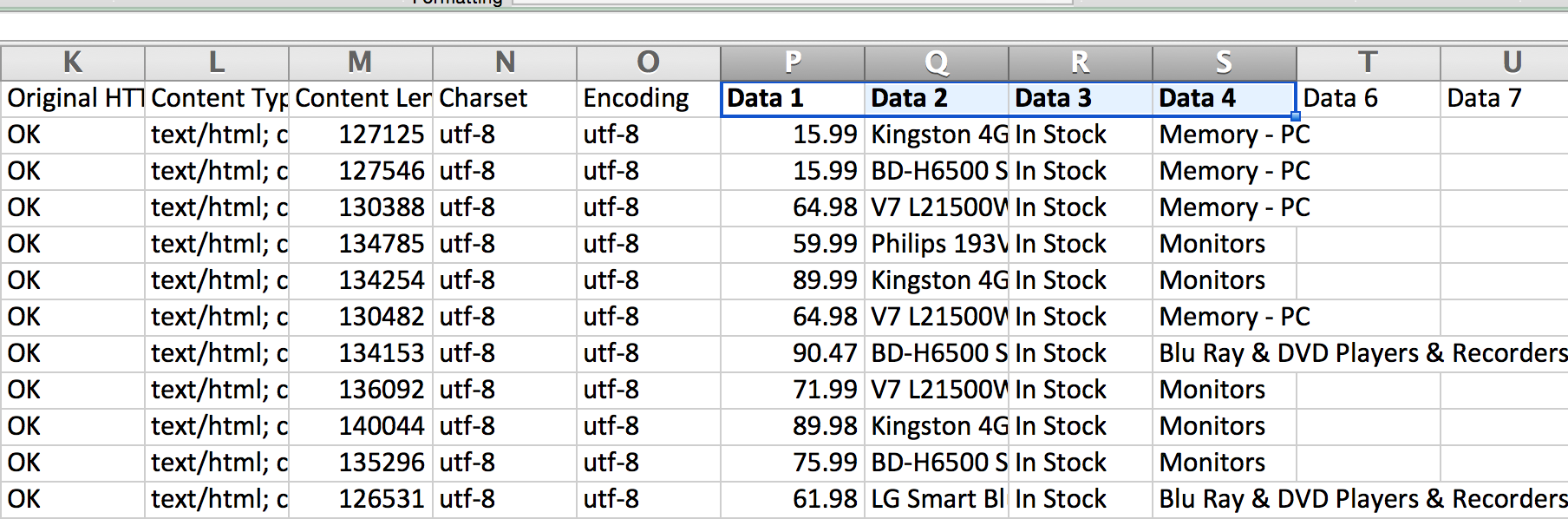
Немного подождав, вы увидите таблицу с дополнительными данными по каждому URL-адресу, и затем вы получите все значения в столбцах с заголовками «Data 1», «Data», «Data 3».
В таблице выше показаны два фрагмента данных, которые я вытащил для URL-адреса товара на Ebuyer.com (название и цена). Теперь нужно лишь добавить все URL-адреса в URL Profiler и запустить его точно таким же образом. Вот как выглядит моя окончательная таблица:
Как вы видите, я также получил данные о том, имеется ли товар в наличии в настоящее время, и в какой категории он размещен на сайте.
Шаг 5: Организация данных в таблице
Четвертый и заключительный шаг в этом процессе - организовать все данные, которые вы извлекли. Вам не нужны все дополнительные данные, которые URL Profiler подтягивает по умолчанию (например, TLD, HTTP Status, Encoding и др.), так что я бы просто удалил все лишнее, оставив только URL-адрес и данные, которые вы извлекли.
Далее, измените заголовки столбцов (Data 1, Data 2, Data 3 …) на что-то более описательное, например, «Цена».
Наконец, назовите таблицу по имени конкурента и дате извлечения данных. Далее можно создать отдельную таблицу, содержащую данные по всем конкурентам, чтобы сделать полный сравнительный анализ.
Честно говоря, вы можете выбрать то, что лучше работает для вас, чтобы просмотреть все эти данные, поскольку они будут варьироваться в зависимости от проекта.
|
|
|
 |

|
Здесь присутствуют: 1 (пользователей: 0, гостей: 1)
|
|
|
|