|
|
A/B тесты креативов для App Store: ошибки, решения
|
 |
17.04.2018, 22:37
|
|
#1
|
|
Регистрация: 30.07.2014
Сообщений: 474
|
| A/B тесты креативов для App Store: ошибки, решения
|
Жизнь пронизана различными дилеммами, с которыми приходится сталкиваться при принятии решений. Специалисты, занимающиеся продвижением приложений (App Store Optimization, ASO), постоянно сталкиваются с необходимостью делать выбор креативов для улучшения показателя установок приложения. Немедленное решение данной головоломки - протестировать множество креативов и выбрать тот, который будет конвертироваться лучше, чем другие.
Однако при этом опускается тот факт, что данный выход не так прост в реализации и не всегда точен. Это то, что я люблю называть обманом A/B тестирования. Насколько мы все любим «флиртовать» с понятием устранения догадок в процессе принятия решений в рамках ASO, некоторые из самых популярных методов и инструментов A/B тестирования на самом деле совершенно неточны.
Например, инструменты A/B тестирования и калькуляторы являются недорогими (или даже бесплатными), простыми в использовании и поэтому чрезвычайно популярными в нашей отрасли. Однако многие из этих калькуляторов подвержены статистическим ошибкам, которые приводят к неверным результатам. Такие ошибки чаще всего вызваны тем, что статистики называют апостериорным теоретизированием, которое принципиально искажает результаты статистического анализа.
Я сделаю все возможное, чтобы помочь вам лучше понять процесс A/B тестирования, где популярные калькуляторы ошибаются, и я предоставлю вам информацию о том, почему StoreIQ™ оказался самым статистически обоснованным и эффективным способом тестирования креативов.
Начнем с обсуждения основ процесса статистического тестирования.
Процесс A/B тестирования
На практике большинство специалистов применяют общий статистический метод проверки гипотез. С точки зрения ASO, например, проверка гипотез может быть использована для определения существования разницы между двумя разными креативами относительно уровня конверсии (CVR, conversion rate).
A/B тестирование состоит из четырех ключевых этапов.
1. Определение нулевой гипотезы
Процесс тестирования начинается с гипотезы, которая, по сути, является заявлением о данных, которые мы хотели бы опровергнуть. Поскольку мы хотим выяснить, есть ли разница между двумя группами, мы хотели бы опровергнуть мнение о том, что разницы нет.
В примере тестирования двух разных app store креативов мы хотим опровергнуть мнение о том, что между двумя креативами нет разницы в CVR. Поэтому нулевая гипотеза утверждает, что нет никакой разницы в CVR для креатива «a» и креатива «b».
Следовательно, альтернатива нулевой гипотезе заключается в том, что существует разница в CVR для креатива «a» и креатива «b».
Этот набор гипотез называется двусторонним критерием.
2. Создание эксперимента
Следующим шагом является проектирование эксперимента. При A/B тестировании креативов необходимо учитывать различные статистические факторы. Вот важные факторы, которые необходимо учитывать на стадии проектирования:
• Является ли выборка репрезентативной для целевой группы населения?
• Каков минимальный размер выборки?
• Насколько правильно мы рандомизируем пользователей по различным вариантам?
• Какие факторы могут повлиять на результаты (например, время дня, день недели и т. д.)?
• В чем смысловая разница в вариациях?
Эти факторы не только актуальны для успешного создания эксперимента, но и необходимы для проведения действительного испытания.
3. Сбор данных
После разработки эксперимента пришло время собирать данные. Сбор данных включает использование платформы, которая может представлять различные креативы, которые вы хотели бы протестировать на пользователях из широкого спектра источников таргетинга и трафика.
4. Анализ данных
После того, как мы собрали данные, мы применяем статистическую формулу, которая делает вывод, являются ли результаты значимыми или нет. Значимость является измерением вероятности того, что нулевая гипотеза верна. Поскольку наша цель в проверке гипотез состоит в том, чтобы опровергнуть нулевую гипотезу, то это измерение должно быть низким (например, уровень значимости 5% является наиболее распространенным порогом, используемым для проверки гипотез, его также можно назвать 95% уровнем доверия).
Ограничения A/B тестирования в ASO
Существует несколько ограничений, с которыми вы сталкиваетесь при применении традиционного процесса A/B тестирования к ASO. Основное ограничение связано с тем, что результаты A/B тестирования могут быть неустойчивыми при тестировании с течением времени. То есть ранжирование вариаций может меняться часто, даже ежедневно. В этом случае вы можете прийти к выводу, что в первый день вариант «а» выиграл, хотя если подождать еще один день, вы увидите, что вариант «b» на самом деле работает лучше.
Внедрение неправильного варианта на основе этого теста может стоить вам добавленных пользователей, которые бы установили приложение, если бы им была показана лучшая вариация. Проблема в том, что традиционный процесс A/B тестирования полностью игнорирует периодические изменения данных.
Кроме того, когда вы тестируете два варианта, которые похожи друг на друга, разница в показателе CVR, как правило, чрезвычайно мала. В этих случаях невозможно достичь значимости при малых размерах выборки. Таким образом, этот параметр требует очень большого размера выборки, который является дорогостоящим при использовании операционной среды (sandbox solution).
В чем ошибаются популярные калькуляторы A/B тестов
Самая большая проблема многих разработчиков приложений при использовании инструментов A/B тестирования заключается в том, что после применения выигрышных вариаций они не видят реальных результатов в app store. Это является прямым результатом того, что большинство инструментов A/B тестирования основываются на неправильной формуле.
Эта формула строится на том, как калькуляторы подходят к процессу A/B тестирования. Вместо того чтобы начинать процесс с определения гипотезы, они сначала наблюдают результаты A/B теста, а затем определяют гипотезу на основе того, что они наблюдали. Этот процесс называют «апостериорным теоретизированием» или выдвижением гипотезы, когда результаты уже известны (Hypothesizing After the Results are Known (HARKing), что считается некорректным в научном сообществе.
В нашем примере A/B теста формульное определение этого типа гипотез определяется, как креатив с большим значением CVR превосходит другой креатив.
Эта гипотеза называется односторонним критерием. Обратите внимание на разницу:
Предпосылка A/B теста должна заключаться в том, что значения показателя CVR являются случайными переменными, таким образом, наблюдения могут рассматриваться как случайные результаты статистического процесса. Как только у нас есть данные, и мы основываем нашу гипотезу на них, мы минимизируем случайность, присущую статистической настройке теста. Поскольку мы не можем узнать, какой креатив лучше другого без проведения тестирования, наша гипотеза должна заключаться в том, что они разные, а не в том, что один лучше другого.
Впоследствии, в ретроспективном теоретизировании вы, в конечном итоге, используете формулу, которая всегда будет давать более низкую значимость, что приводит к более высокой вероятности ложного отклонения нулевой гипотезы.
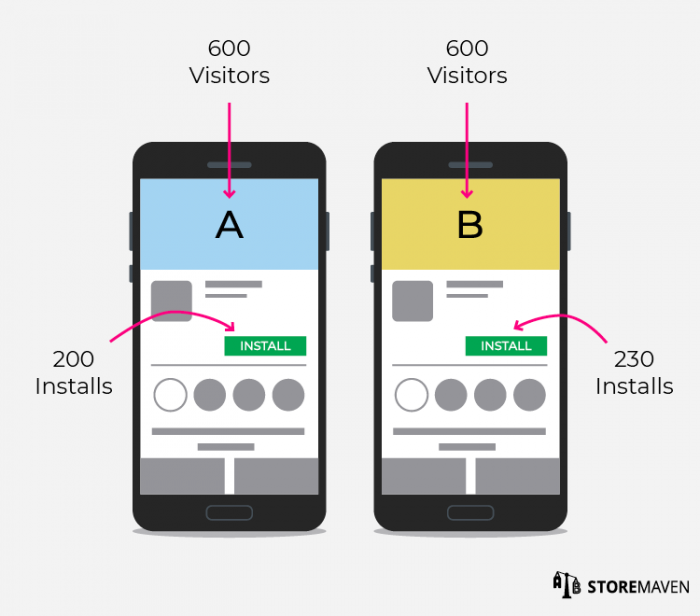
Вот пример того, как эта псевдо-методология может привести к ошибочным результатам. Предположим, вы тестируете два разных графических объекта.
Опять же, мы проводим анализы, используя обычно используемый уровень значимости 5% (уровень доверия 95%). Теперь предположим, что 600 посетителям показали два этих объекта. Графический объект «a» получает 200 установок, графический объект «b» - 230 установок.
Если мы используем традиционный процесс A/B тестирования, то нулевая гипотеза будет состоять в том, что графический объект «a» и графический объект «b» имеют одинаковый показатель CVR. Следовательно, альтернативная гипотеза заключается в том, что они не равны. Если мы затем подставим данные выше в широко используемую формулу различия образцов, мы получим несущественное p-значение. (P-значение - вероятность того, что альтернативная гипотеза неверна).
Обратите внимание, что p-значение для этого параметра равно 0,07, что превышает уровень значимости 5%. Если мы используем ретроспективный подход теоретизирования и применим те же точные данные в формулу, то мы получим ровно половину от значения значимости.
Это побудит нас ошибочно отвергнуть нулевую гипотезу, поскольку p-значение теперь ниже уровня значимости. Следовательно, в дополнение к присущим ограничениям применения традиционного процесса A/B тестирования к ASO, которые были ранее перечислены, популярные калькуляторы еще больше ошибаются в расчетах, которые они используют в процессе теста.
StoreIQ™ - оптимальное решение для проведения тестирования
Опираясь на big data, мы изобрели StoreIQ™, чтобы помочь себе найти паттерны и производить тестирование app store креативов в рамках научного метода, который дает реальные результаты. StoreIQ™ является запатентованным, предсказательным алгоритмом, который оценивает CVR тестовых вариаций быстро и гораздо более точно, чем стандартные методологии A/B тестирования или калькуляторы.
Необходимый размер выборки для StoreIQ ™ оптимизирован для того чтобы доставить высоко точный результат, одновременно сохраняя размер выборки небольшим. Наш алгоритм предсказывает, когда вариация будет недостаточно эффективной, и он немедленно останавливает ее работу, чтобы траффик не был потрачен впустую на вариант, который вряд ли выиграет. Это экономит нашим клиентам 30-50% стоимости отправки трафика на тест, сохраняя при этом точные результаты. Это доказано реальными результатами в app store.
Кроме того, поскольку существует множество внешних переменных, которые могут повлиять на эксперимент, StoreIQ™ также развивается по мере прогресса теста и реагирует на изменения внешних факторов вопреки статическому подходу к A/B тестам. Одним из таких факторов является периодическое изменение данных при тестировании в течение продолжительного периода времени и времени суток.
Хотя по этому вопросу можно сказать гораздо больше, я надеюсь, что вы теперь понимаете основы распространенных неточностей A/B тестирования, и почему StoreIQ™ является оптимальным решением для точного и экономичного тестирования креативов.
|
|
|
 |

|
Здесь присутствуют: 1 (пользователей: 0, гостей: 1)
|
|
|
|